前言
ELK是最近比较流行的免费的日志系统解决方案,注意,ELK不是一个软件名,而是一个解决方案的缩写,即Elasticsearch+Logstash+Kibana(ELK Stack)。这哥几个都是java系的产品,但是众所周知,java的东西很吃内存和CPU,Logstash在当作为收集日志的Agent时,就显得太过臃肿了。听说直播平台“斗鱼”团队很为logstash占用资源的情况很而苦恼,后来为了解决这个问题,他们自己写了一个agent。不过后来官方在logstash-forwarder的基础上推出了beat系列,里面包括四个兄弟,分别是:Packetbeat(搜集网络流量数据);Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);Filebeat(搜集文件数据);Winlogbeat(搜集 Windows 事件日志数据)。而Filebeat也就这样加入了“日志收集分析”的团队里,所以虽然大家还是习惯性的叫ELK,其实准确的说法已经是ELKB了。
ELKB这几个哥们的分工如下:
- Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
- Logstash:数据收集额外处理和数据引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
- Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
- Filebeat:ELK 协议栈的新成员,在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
设计架构

本文的设计结构就是这样,其中红色的redis/RebbitMQ部分可以省略(我这个例子里暂省略),让日志直接传递到logstash,如果日志量较大,最好还是添加上redis,同时再横向扩容Elasticsearch,搞成一个集群。
对于这几个模块服务器多说几句:
1)Logstash要选择计算能力强的,CPU和内存比较丰满的;
2)Elasticsearch要选择磁盘容量大的,同时CPU和内存也比较丰满的;
实验软件版本
Elasticsearch 5.6.4
Logstash 5.6.4
Kibana 5.6.4
Filebeat 5.6.4
Java 1.8+,安装方法:http://blog.51cto.com/chenx1242/2043924
由于ELKB这几个东西都是墙外的,墙内的下载可能会比较费劲。所以我稍后会把所有ELKB的5.6.4程序都放在51CTO的存储空间里,需要的朋友可以去下载,还是那话,虽然ELK升级频率很快,但是5.6.4已经足够稳定了。
实验服务器情况

安装Elasticsearch 5.6.4
以下所有操作都是root下进行的:
1
2curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.4.rpm
rpm -ivh elasticsearch-5.6.4.rpm
然后编辑/etc/elasticsearch/elasticsearch.yml,不然的话logstash无法与之相连:
1
2
3cluster.name: my-application #如果是集群的es就把这个打开,Elasticsearch 启动时会根据配置文件中设置的集群名字(cluster.name)自动查找并加入集群,端口是9300
network.host: 0.0.0.0 #取消注释,并且改成0.0.0.0
http.port: 9200 #取消注释
保存之后,启动并且添加开机启动:
1
2systemctl start elasticsearch
systemctl enable elasticsearch
使用curl localhost:9200能看到这样的情景就证明已经成功启动了: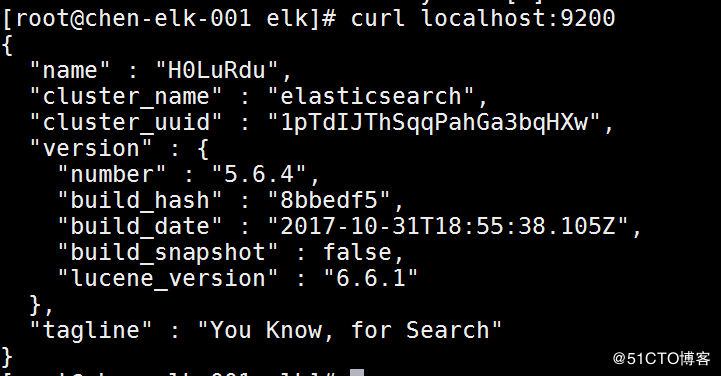
安装kibana 5.6.4
以下所有操作都是root下进行的:
1
2
3
4curl -L -O https://artifacts.elastic.co/downloads/kibana/kibana-5.6.4-linux-x86_64.tar.gz
tar xzvf kibana-5.6.4-linux-x86_64.tar.gz
cd kibana-5.6.4-linux-x86_64/
vim config/kibana.yml
把kibana.yml里的server.host: localhost改成server.host: 0.0.0.0,然后保存退出,在kibana的bin文件夹里执行./kibana即可。如果要后台启动就是nohup /kibana安装路径/bin/kibana &。
启动之后,如图:
安装Logstash 5.6.4
以下所有操作都是root下进行的:
1
2curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-5.6.4.rpm
rpm -ivh logstash-5.6.4.rpm
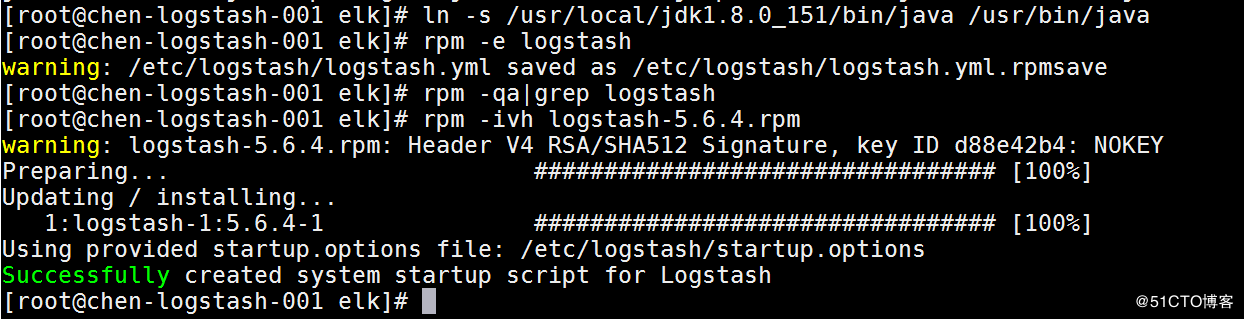
如果安装的时候爆错:/usr/share/logstash/vendor/jruby/bin/jruby: line 388: /usr/bin/java: No such file or directory。那么就先which java查看一下java的文件,然后做一个软连接过去,然后重装logstash即可,如图:
用户可以使用TLS双向认证加密Filebeat和Logstash的连接,保证Filebeat只向可信的Logstash发送加密的数据(如果你的logstash和filebeat是内网通信,而且你认可当前内网的安全度,这一步可以省略)。同样的,Logstash也只接收可信的Filebeat发送的数据。这个功能默认是关闭的,要开启的话需要先vim /etc/pki/tls/openssl.cnf,如图: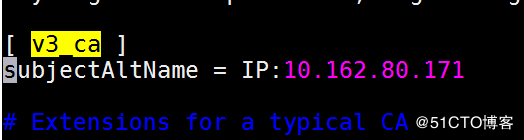
找到[ v3_ca ]的字段,在底下添加subjectAltName = IP:logstash的内网IP字段,保存退出来到/etc/pki/tls/,执行下面命令:
1
openssl req -x509 -days 365 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
来生成一个期限为365天的IP SAN证书对,如果想生成一个十年的证书,就把365改成3650即可,如图:
安装完毕之后,vim /etc/logstash/logstash.yml,编辑成如下的样子:
然后在/etc/logstash/下手动建立一个目录conf.d,在conf.d里新建一个logstash.conf的文件,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39$ cat /usr/local/logstash/config/conf.d/logstash.conf
#在输入部分,配置Logstash通信端口以及添加SSL证书,从而进行安全通信。
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
#在过滤器部分,我们将使用Grok来解析这些日志,然后将其发送到Elasticsearch。以下grok过滤器将查找“syslog”标记的日志,并尝试解析它们,以生成结构化索引。
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
#输出部分,我们将定义要存储的日志位置
output {
elasticsearch {
hosts => [ "10.162.80.192:9200" ] #这个地址是elasticsearch的内网地址
index => "filebeat-%{+YYYY.MM.dd}" #设定这个是索引
#index => "auclogstash-%{+YYYY.MM.dd}" #这行是后来作实验的,可以忽视
user => elastic #这个是为了将来装x-pack准备的
password => changeme #同上
}
stdout {
codec => rubydebug
}
}
然后就是启动并且添加开机自启动:
1
2systemctl start logstash
systemctl enable logstash
安装filebeat
以下所有操作都是root下进行的,在模块服务器上安装filebeat的方法如下:
1
2curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.4-x86_64.rpm
rpm -ivh filebeat-5.6.4-x86_64.rpm
之前在logstash上生成了一个IP SAN证书,现在需要把这个证书传递给filebeat的机器里,使用scp语句如下:
1
scp -pr root@10.162.80.171:/etc/pki/tls/certs/logstash-forwarder.crt /etc/ssl/certs/ #10.162.80.171就是logstash的内网IP
输入logstash的密码,并且密钥文件复制完毕之后,需要修改filebeat.yml,于是#vim /etc/filebeat/filebeat.yml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[root@func-auc-001 log]# grep -iv '#' /etc/filebeat/filebeat.yml | grep -iv '^$'
filebeat.prospectors:
- input_type: log
paths:
- /mnt/hswx/auc/logs/*.log #这个是那个auc模块的路径
- /第二个日志路径/*.log #如果有第二个文件路径的话
tail_files: true #从文件末尾开始读取
document_type: "newnginx-api" #logstash那里已经设定了index,如果要使用了document_type,那么在logstash的index就要这么写:"%{type}-%{+YYYY.MM.dd}"
# 以下是规避数据热点的优化参数:
spool_size: 1024 # 积累1024条消息才上报
idle_timeout: "5s" # 空闲5s上报
output.logstash:
hosts: ["10.162.80.171:5044"] #这个地方要写logstash的内网地址
ssl.certificate_authorities: ["/etc/ssl/certs/logstash-forwarder.crt"] #这里就是刚刚复制的那个密钥文件路径
#注意上面是ssl而不是tls,1.0版本才是tls,如果这个写错了,启动的时候会出现“read: connection reset by peer”的错误
注意!Filebeat的配置文件采用YAML格式,这意味着缩进非常重要!请务必使用与这些说明相同数量的空格。
保存之后,使用/etc/init.d/filebeat start启动filebeat,如图:
故障解决
ELK几个部件现在都已经启动了,并且互相telnet端口都是通的,在elasticsearch的服务器上使用curl -XGET 'http://elasticsearch内网IP:9200/filebeat-*/_search?pretty'却出现这样的情况: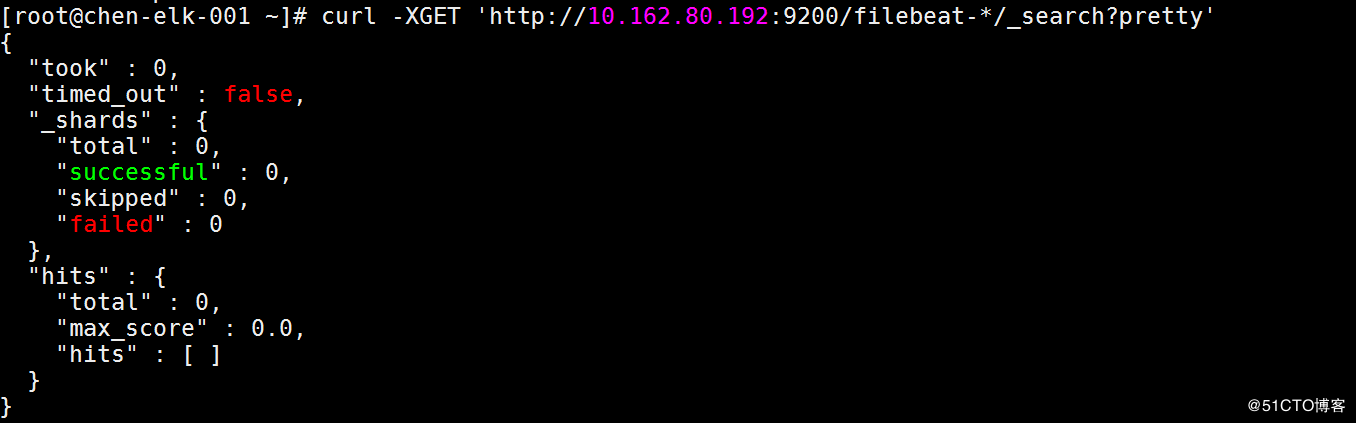
而使用tailf /var/log/filebeat/filebeat去查看filebeat的日志是这样的:
再看看logstash-plain.log,里面的情况是这样的:
从此可见,filebeat与logstash的联系是error状态,那么停止filebeat的进程,改用/etc/init.d/filebeat start -c /etc/filebeat/filebeat.yml,重新在elasticsearch的服务器上使用curl -XGET 'http://elasticsearch内网IP:9200/filebeat-*/_search?pretty'发现已经成功读到了我们之前配置的目录“/mng/hswx/auc/log”,如图: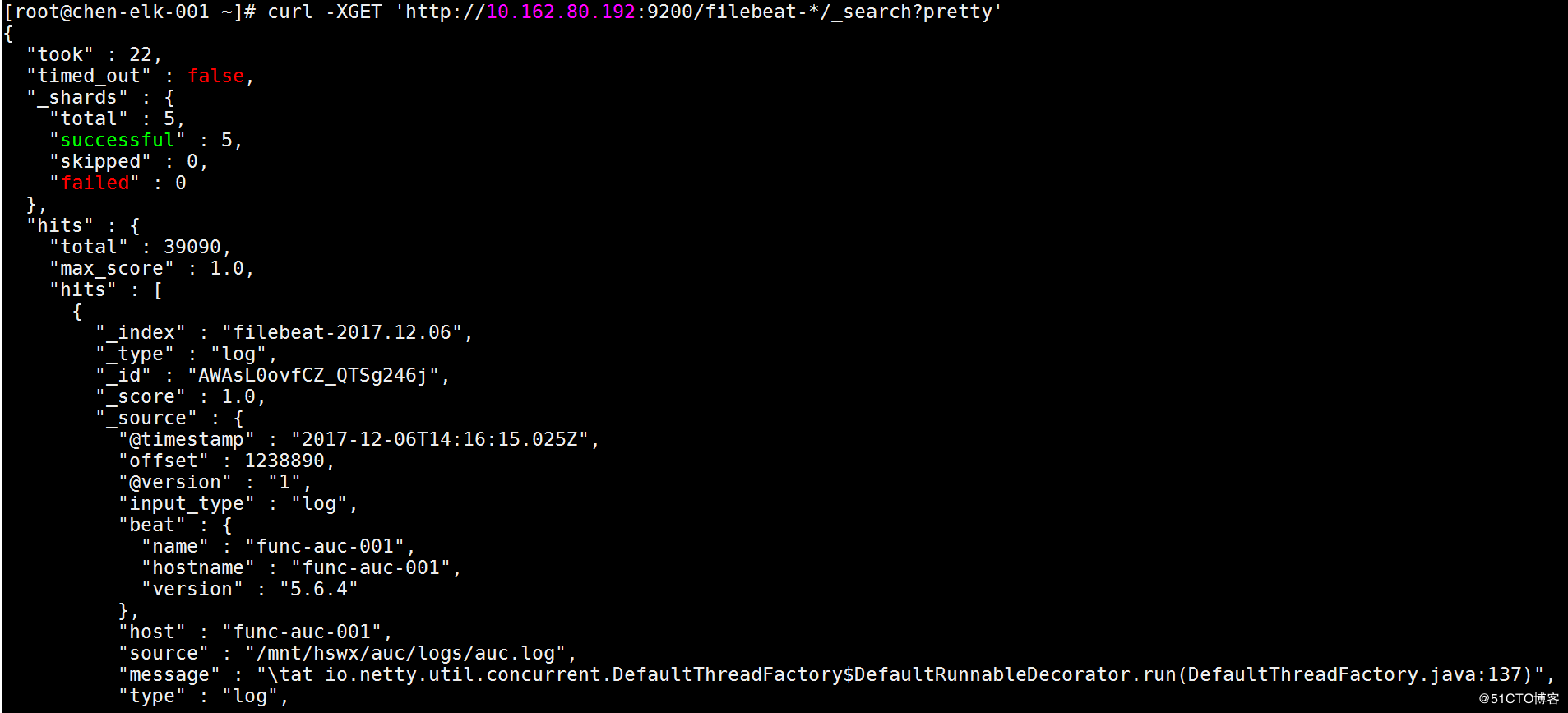
配置kibana
在浏览器输入kibana服务器外网IP:5601打开kibana的web界面,把idenx pattern的地方改成filebeat-*(同之前配置的index索引一致),然后点击create,如图:
然后就得到了细节的web界面,如图: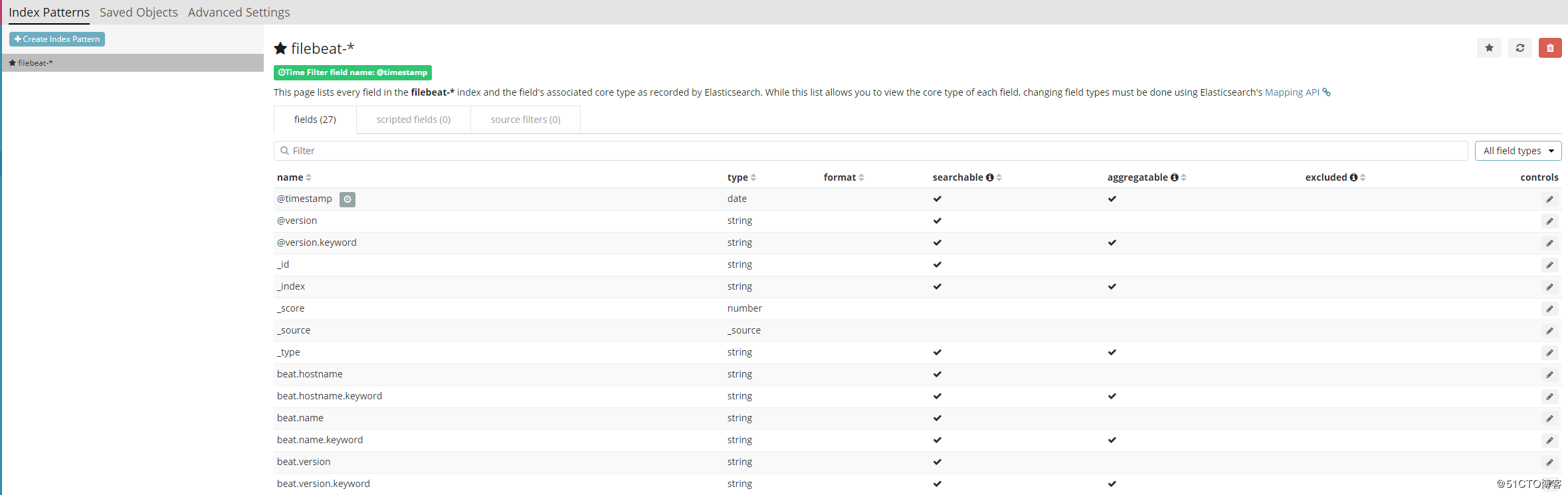
点击左侧框的Discover,就会看到梦寐以求的日志web界面,如图: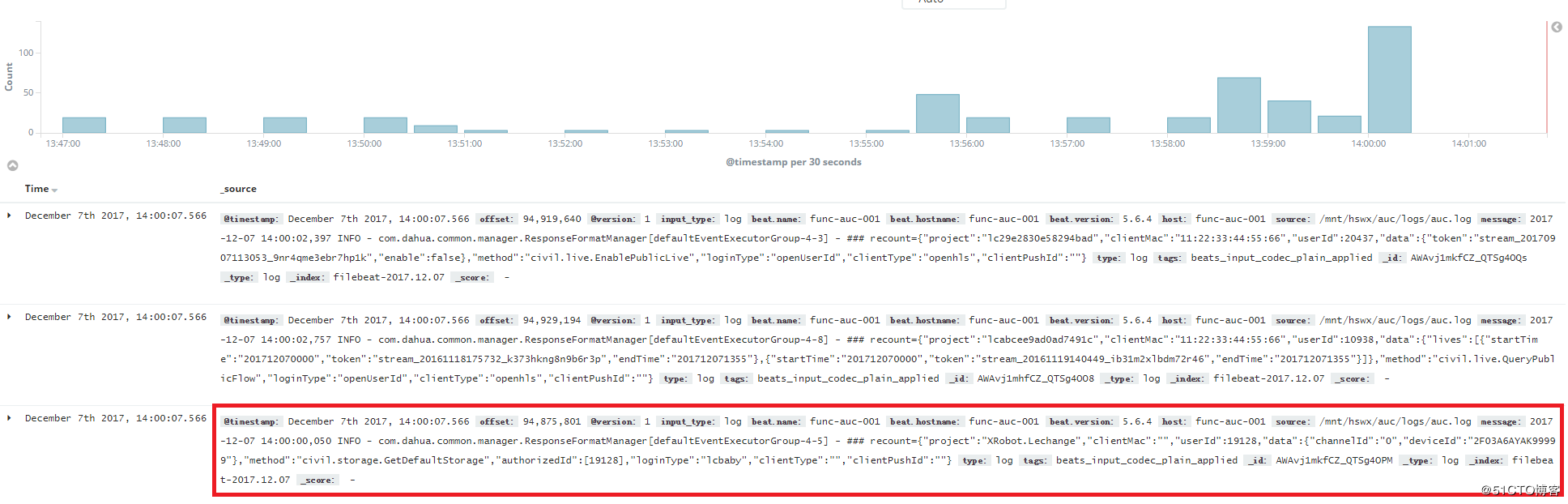
看一下红色框的内容里面有时间,有host主机,有source来源,还有具体的日志信息,我们再去func-auc-001这个日志源主机上查询一下日志:
两个日志是一样的,可见实现了预期的日志展示的目标!
最后一步,就是把kibana与nginx联系起来(也可以把kibana做阿里云负载均衡的后端服务器),这样通过nginx/负载均衡来访问kibana的界面,对kibana来说更安全。配置端口监听如图,再把kibana服务器挂在负载均衡后面即可。
参考资料
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk/
http://www.jinsk.vip/2017/05/24/elksetup/
https://renwole.com/archives/661
https://www.zybuluo.com/dume2007/note/665868
https://www.elastic.co/guide/en/beats/libbeat/5.6/getting-started.html
https://discuss.elastic.co/search?q=ERR%20Failed%20to%20publish%20events%20caused%20by%3A%20read%20tcp
http://jaminzhang.github.io/elk/ELK-config-and-use-Filebeat/ (这个博主很好,但是就是博客无法留言,这点比较坑)

