准备工作
首先,先下载一个elastic网站上下载一个它提供的demo—莎翁的《亨利四世》,下载地址是https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json 。
打开这个json字符串,里面就是《亨利四世》的话剧剧本,长得是这个样子:
可以看到里面有play_name、speaker、speech_number、line_id等等名称,每个名称后面都有一个对应的值。
然后启动elasticsearch,按照上面的文件格式生成索引。语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14curl -XPUT http://localhost:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" }, #确定type是字符
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" }, #确定type是数字
"speech_number" : { "type" : "integer" }
}
}
}
}
';
导入刚刚下载的那个json:curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
具体elasticsearch的增删改查语法可以参看阮大师的http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html ,个人建议将elasticsearch和mysql对比一下,这样更方便理解。
然后后台启动kibana,确认5601端口已经stand by,如图:
然后在浏览器地址栏输入服务器外网ip:5601打开kibana。
导入数据结束之后,使用curl 'localhost:9200/_cat/indices?v',去查看一下效果,如果看到index里有shakespeare那一栏就是导入成功了,如图: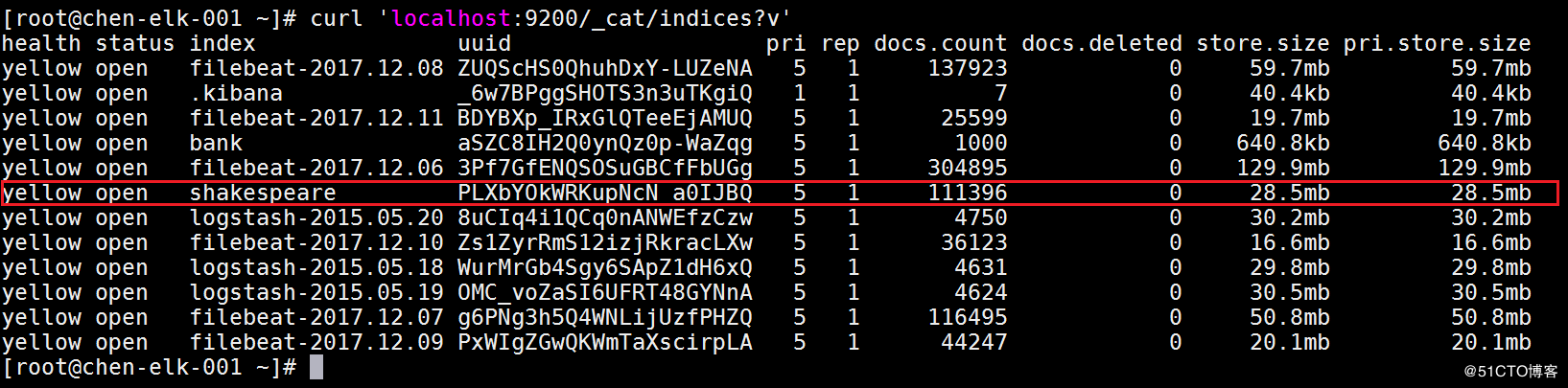
在启动Kibana后,Kibana会自动在配置的es中创建一个名为.kibana的索引(上图第二个),这个索引用来存储数据,注意!不要删除了它。
Kibana的界面搜索
如果此时的kibana里是第一次配置的话,那么第一步就是配置新索引,我们之前在生成索引的时候写的是shakespeare,那么现在也写shakespeare,然后点击create,如图: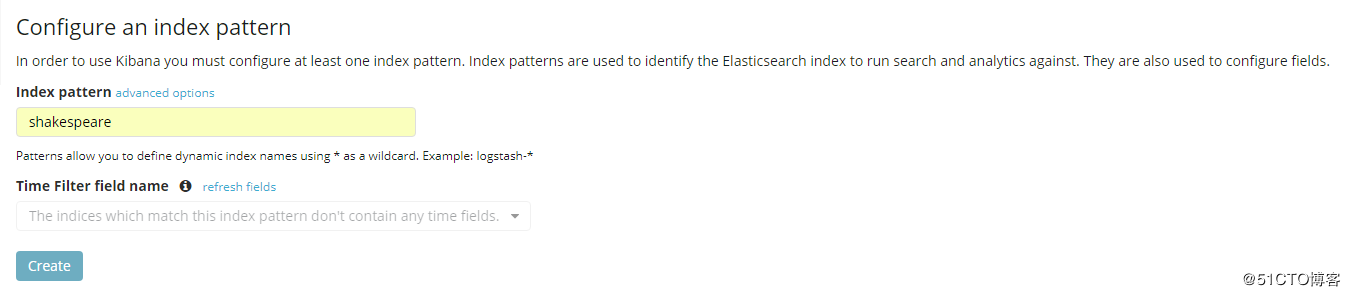
然后在菜单栏左侧的discover里选择刚刚建立的shakespeare,就会看到这样的东西: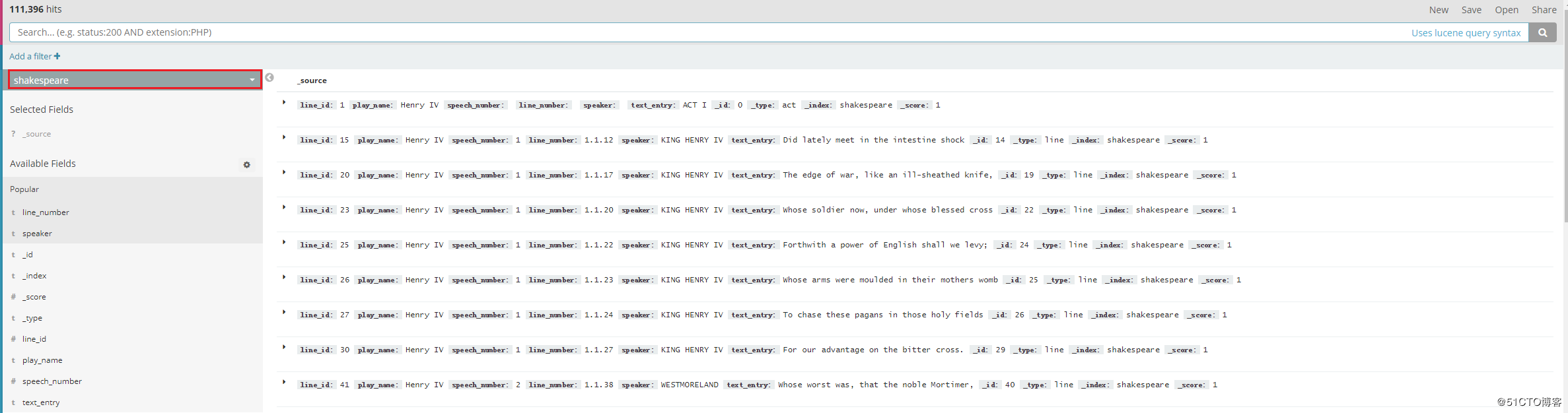
在Search上就可以进行搜寻,比如说我搜寻freedom,如图:
如果我搜寻KING HENRY IV,他不分大小写的把所有king、henry、iv都搜索出来。
如果我想搜寻line_id的第一行到第三行,那么语句就是line_id:[1 TO 3],如图:
如果想在上面的基础上进一步细化,比如说要在line_id是从第一行到第三行,同时_type是scene的语句:line_id:[1 TO 3] AND _type:scene:
假如不想要scene,那么就把AND改成NOT。
如果这个时候只想关注一些指定的字段,那么可以将鼠标移动到索引下面的字段上,然后选在add即可,同样的移动上面已经选择的字段选择remove进行移除,比如我们试一下这个speaker:
add之后在点击右侧的具体的speaker,就会看到里面的细节,比如这位westmoreland(威斯摩兰伯爵):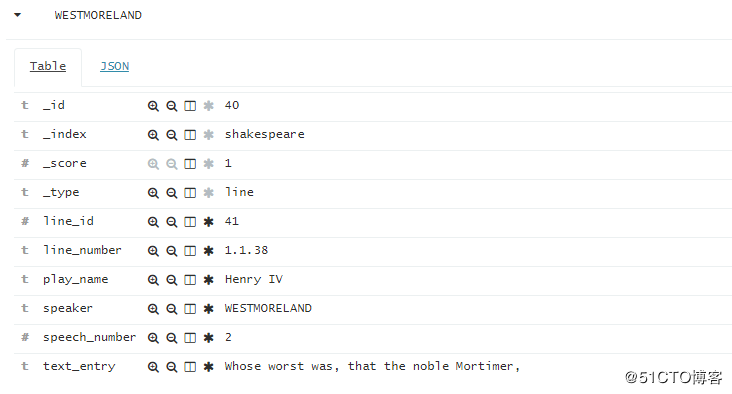
这个时候就能看见这位伯爵大哥的台词细节,在第几场的第几节,说的是什么台词。再返回菜单左侧点击这个speaker,我们还会看到一个比重: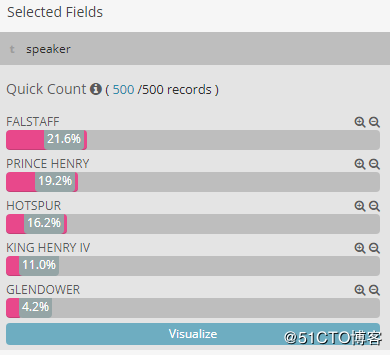
从这里就很清晰的看到,FALSTAFF(法斯塔夫)这个哥们的台词最多,也符合书里塑造的那个嗜酒话痨的艺术形象。而我们的KING HENRY IV(亨利四世)的台词只是第四位,占比重11%而已…
这样具体的搭配搜索之后,可以点击界面右上侧的save进行保存搜寻结果,再搭配share分享搜索结果的url网址,如图:
Kibana的图像化展示
Kibana也能做到类似grafana那样的炫酷图象化展示,更加立体的表现日志情况,首先选择左侧菜单栏里的Visualize(可视化):
然后点击Create a Visualization,里面既有很多种图形供你选择,有饼型,有箭头的,有文字的,有仪表盘的,如图:
我们这里先建立一个饼型的,还是上面那个台词多少的例子,首先选择shakespeare作为数据源,然后点击split slices,如图:
然后在Aggergation里选择Terms,然后在Field里选择Speaker,size那里写8,最后点击上面的那个三角播放键,看看结果: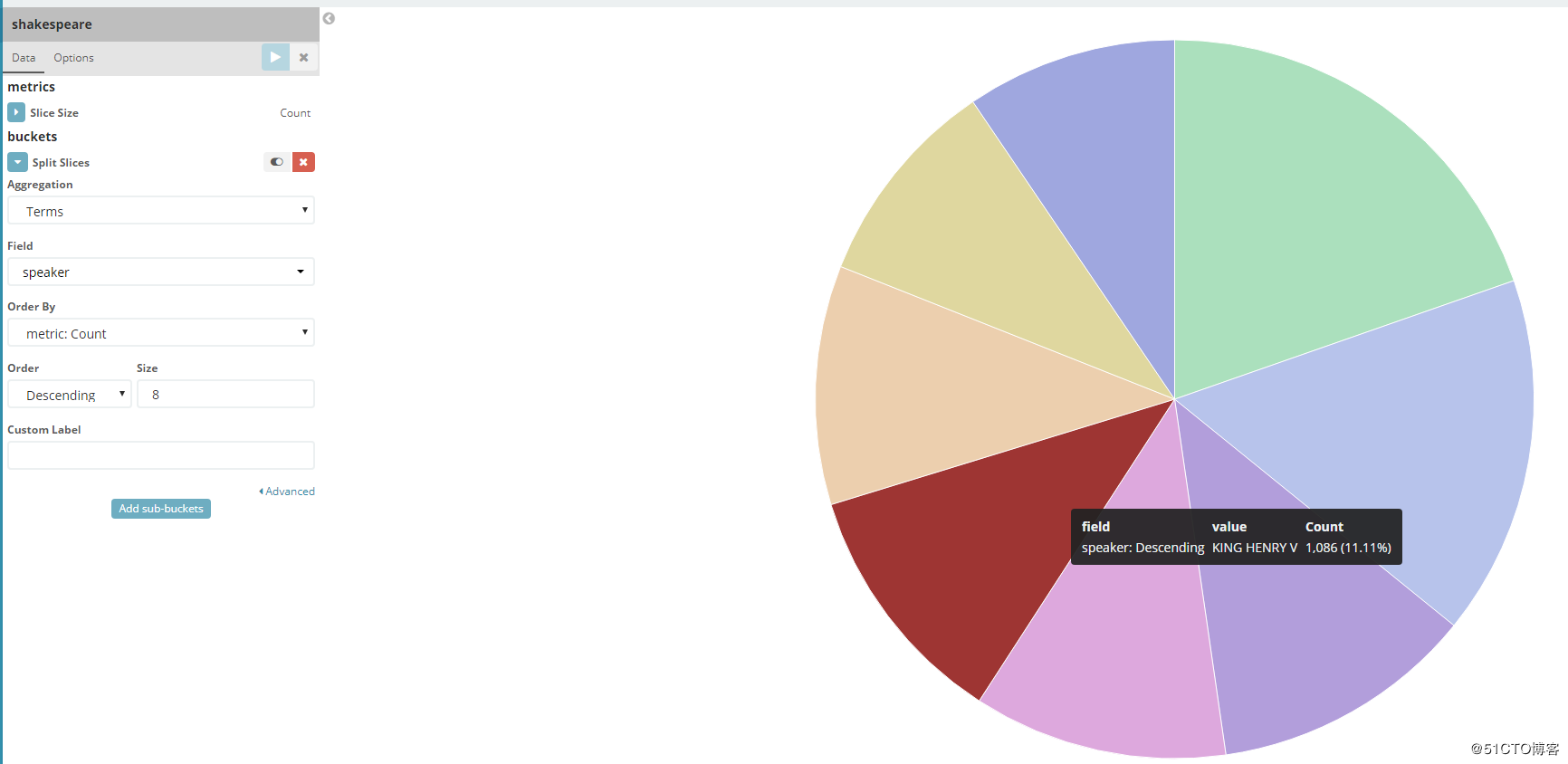
这就很清晰的看出,亨利四世一共说了1086句话,占比11.11%。
如果我们再加一个Split Slices,这一次在原有的specker的基础上选择play_name,图象变成了一个同心圆,最外面的一层就是新增的“play_name”的情况,如图显示FALSTAFF的所有台词会在两个play_name里出现: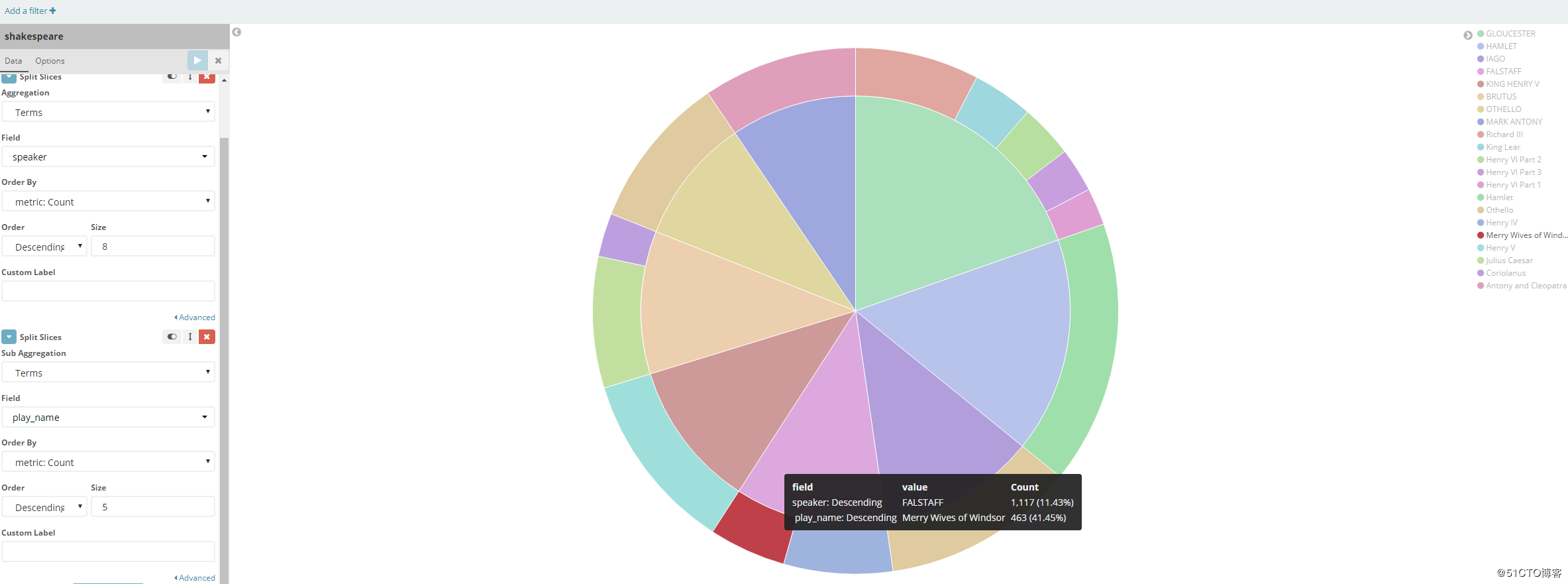
如果这个盘子里不想统计FALSTAFF这个话包,就添加一个过滤器,选择speaker is not,后面写上FALSTAFF即可,如图: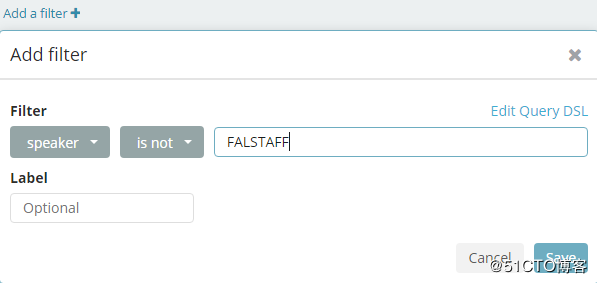
效仿刚才的方法也可以做一个仪表盘,如图: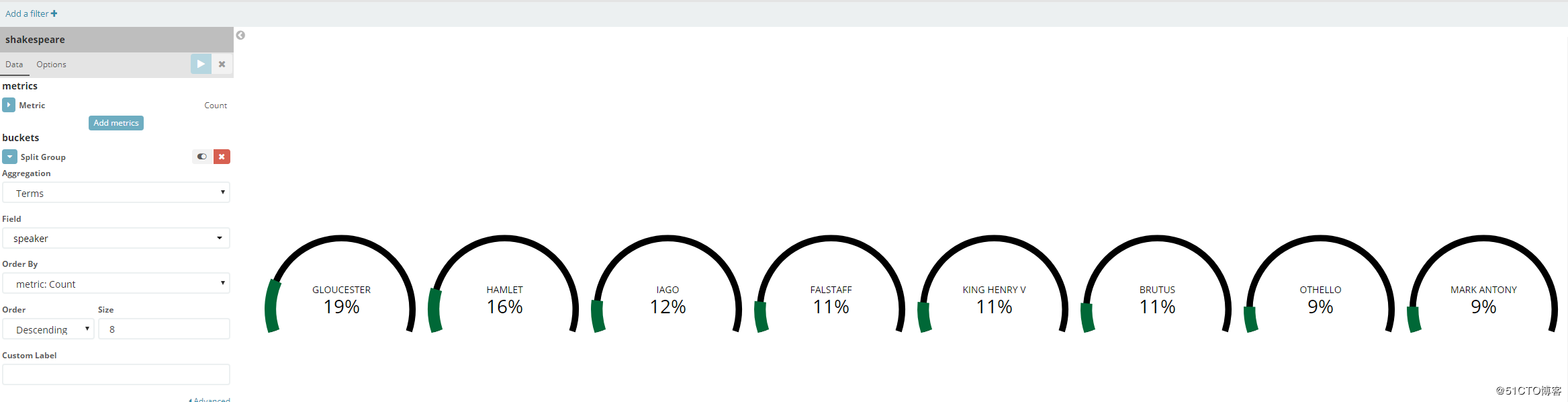
可视化的数据也可以save和share,同样在web界面的右上角。保存的数据是可以在左侧菜单栏里的Dashboard里展示,做成一个类似zabbix那样的展示!

