任务背景
接到金山云报警短信,说某数据库的容量已经达到了90%的水位线,于是登陆控制台查看详细情况。
在控制台首先发现,每一天的磁盘容量的确有所波动,那么就证明开发人员写的“资源回收”模块是在正常运行的,如图: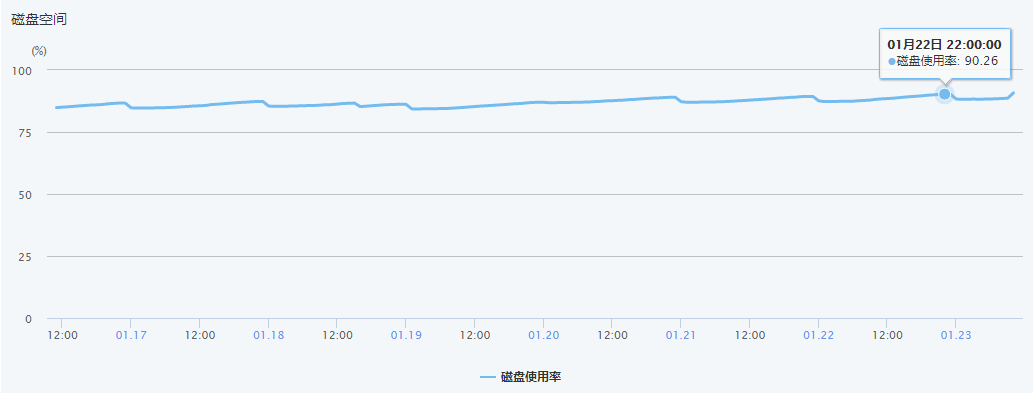
那么就说明没有什么数据是可以删的,既然删不掉多余的数据又不想多掏钱扩磁盘容量,只能从“磁盘碎片”下手了。而InnoDB引擎清理磁盘碎片的命令就是OPTIMIZE。
具体操作
首先我先查询一下所有的“磁盘碎片情况”,使用语句如下:
1
select CONCAT(TABLE_SCHEMA,'.',TABLE_NAME) as 数据表名,concat(truncate(sum(DATA_LENGTH+DATA_FREE+INDEX_LENGTH)/1024/1024,2),' MB') as total_size, concat(truncate(sum(DATA_LENGTH)/1024/1024,2),' MB') as data_size,concat(truncate(sum(DATA_FREE)/1024/1024,2),' MB') as data_free, concat(truncate(sum(INDEX_LENGTH)/1024/1024,2),'MB') as index_size from information_schema.tables group by TABLE_NAME order by data_length desc;
或者使用select table_schema, table_name, data_free, engine from information_schema.tables where table_schema not in ('information_schema', 'mysql') and data_free > 0;也可以,这个是查询data_free大于0的所有表。
然后看到我这个叫history_device_flow_day的表里情况如下: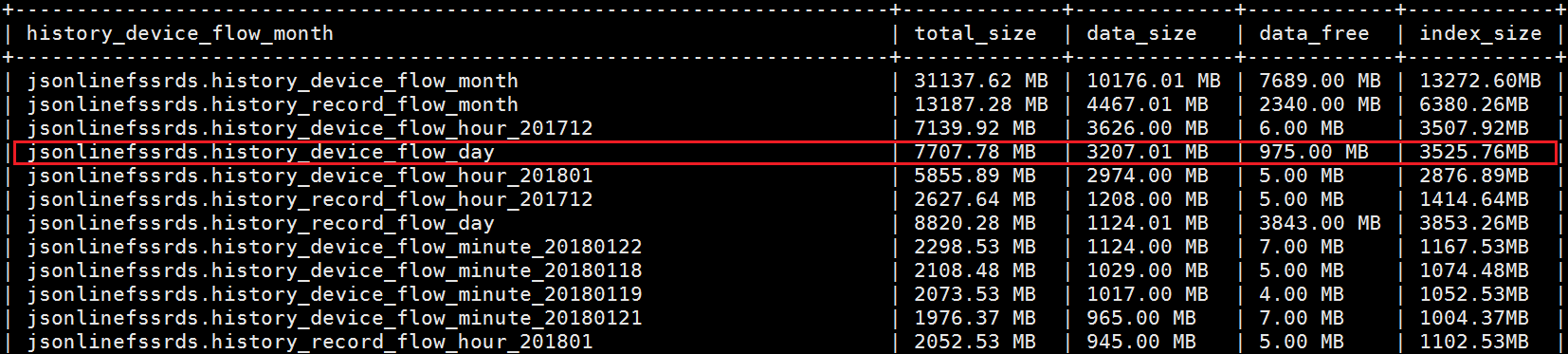
表里的data_free就是磁盘碎片的量,比如我现在要干掉history_device_flow_day里所有的磁盘碎片,是975MB,于是先查询一下这个history_device_flow_day的存储引擎,使用语句如下:
1
show table status from jsonlinefssrds where name='history_device_flow_day';
上面语句里的jsonlinefssrds是对应的数据库,看到的效果如下:
存储引擎是InnoDB,那么就可以启动清除碎片的语句了:OPTIMIZE TABLE 数据表表名;,因为OPTIMIZE TABLE只对MyISAM、BDB和InnoDB表起作用。
再执行了OPTIMIZE TABLE history_device_flow_day;之后,大约9分钟,就会看到“OK”的字样:
估计有的朋友会问,那上面不是明明写了“Table does not support optimize, doing recreate + analyze instead”吗?这个其实无妨,实际上磁盘碎片已经被清除掉了。我们可以再用一次查询磁盘碎片的命令看一下,如图: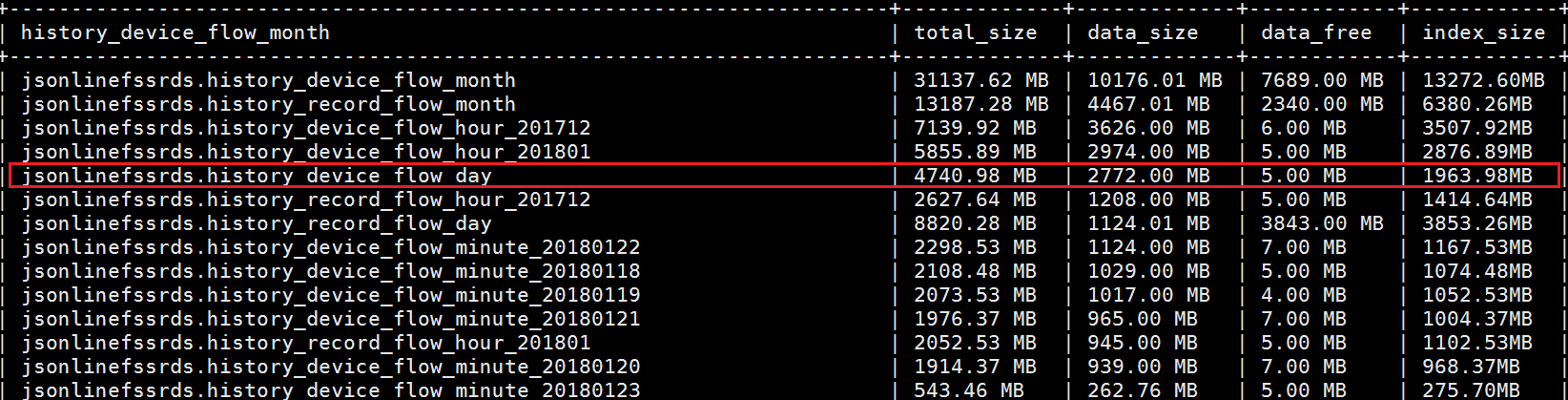
的确释放了900多M。
或者使用ALTER TABLE 表名 ENGINE = Innodb;(只是InnoDB的表可以这么做,而且据说这么做更友好)来达到清理磁盘碎片的目的,这个命令表面上看什么也不做,实际上是重新整理碎片了。当执行优化操作时,实际执行的是一个空的ALTER命令,但是这个命令也会起到优化的作用,它会重建整个表,删掉未使用的空白空间。
补充
为什么会产生磁盘碎片?那是因为某一个表如果经常插入数据和删除数据,必然会产生很多未使用的空白空间,这些空白空间就是不连续的碎片,这样久而久之,这个表就会占用很大空间,但实际上表里面的记录数却很少,这样不但会浪费空间,并且查询速度也更慢。
注意!OPTIMIZE操作会暂时锁住表,而且数据量越大,耗费的时间也越长,它毕竟不是简单查询操作。所以把OPTIMIZE命令放在程序中是不妥当的,不管设置的命中率多低,当访问量增大的时候,整体命中率也会上升,这样肯定会对程序的运行效率造成很大影响。比较好的方式就是做个shell,定期检查mysql中 information_schema.TABLES字段,查看DATA_FREE字段,大于0的话,就表示有碎片,然后启动脚本。
参考资料
http://pengbotao.cn/mysql-suipian-youhua.html
http://irfen.me/mysql-data-fragmentation-appear-and-optimization/

