背景交待
市场运营在手机APP端推送了一个“家装节,部分商品优惠打折”消息,用户可以通过点击这个消息,在APP进入到商城界面,如果是已经登录的用户将通过免登陆直接跳转,如果是没有登录的用户会登陆到登陆界面。但是刚推送就发现,通过这个推送点击,没有正常登陆到商城界面,而是返回了502。
nginx 502的错误,一般来说就是php-fpm的问题,我登陆到电商服务器发现,php-fpm运行正常而且php-fpm的进程数也很正常。但是查看到mysql,发现mysql的CPU飙升,如图: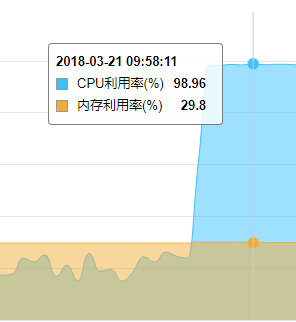
于是登陆到数据库里,使用show processlist一看,数据库里有大量的语句处于sending data状态,而且执行时间令人发指(command项处于Sleep状态的进程表示其正在等待接受查询,因此它并没有消耗任何资源,是无害的):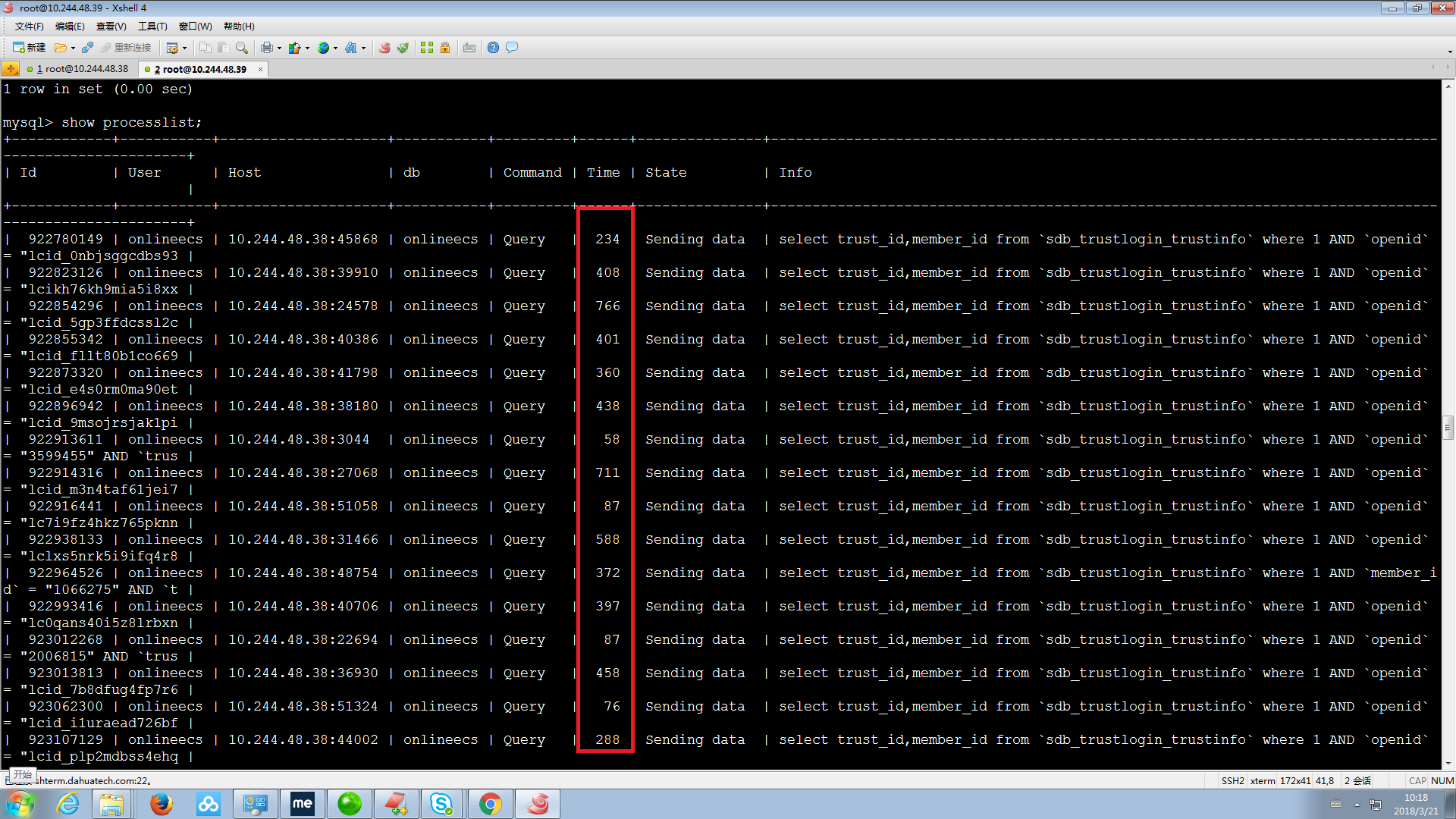
先赶快通知运营先把推送的消息界面停用掉,不要让更多的用户登陆失败。然后写了一个脚本批量的kill掉这些进程,看看能不能让数据库恢复正常,过程如下。
首先先得到show processlist展现的所有的情况:
1
mysql -uroot -p密码 -h数据库地址 -e "show processlist" | grep -i 'Locked' > locked_log.txt
然后获得前面的进程号,并且加上kill的指令:
1
2
3
4
5#/bin/bash
for line in `cat locked_log.txt | awk '{print $1}'`
do
echo "kill $line;" >> kill_thread_id.sql
done
在登陆到数据库,然后执行上面生成的kill_thread_id.sql::
1
mysql>source kill_thread_id.sql
但是发现,kill掉一批之后,又有了新的慢sql出现,CPU依旧高居不下,于是只能跟产品经理说明情况,在征得了产品经理无奈的同意之后,重启了数据库,幸好时间没有很长,就耽误二三分钟而已。重启了之后,CPU就降下去了。赶快叫开发童鞋在线补充一个索引给用户登录的表来解决这个慢sql问题,没有了慢sql就没有了502。
补充nginx499
nginx如果爆错499的话,代表客户端主动关闭连接,原因就是后端脚本执行的时间太长了or数据库有慢mysql,调用方超出了timeout的时间,关闭了连接。
这个时候需要更改一下nginx.conf:
1
2proxy_read_timeout 10s;
proxy_send_timeout 10s;
把上面两个值适度调大然后重启nginx即可。或者就是proxy_ignore_client_abort on;,这话就是让代理服务端不要主动关闭客户端的连接。
参考资料
https://blog.csdn.net/zhuxineli/article/details/14455029
https://segmentfault.com/a/1190000012326158

