具体需求与解决方案
假设我们有一个列表,现在要对列表里进行从大到小排序,然后再获取列表里原来各位元素的索引,怎么办?
1
2#Python2.7
new_list = sorted(enumerate(old_list),key=lambda x: x[1],reverse=True) #old_list就是原列表
举一个详细一点的例子: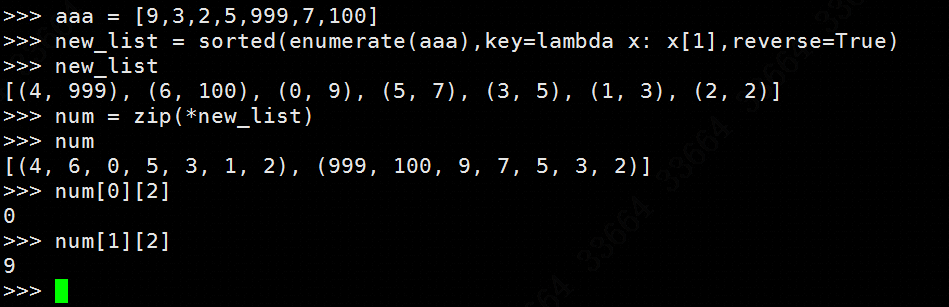
可见原来aaa这个列表的元素虽然经过了大小排序,但是各元素的索引下标没有丢,而且通过zip()方法能拆出来供我们继续使用。
enumerate() 函数
这个enumerate() 函数可以将一个可遍历的数据对象组合一个索引序列,同时列出数据和数据下标,默认情况下标是从0开始的,也可以手动更改,比如:
1
2
3
4
5>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
有了它,我们就可以轻松获取索引下标值了。
sorted(key=lambda)
sorted()是用来排列列表的函数,默认情况下是从小到大排列。如果列表里是每一个元素并不是单纯的一个数字,而是多字段,那么就要规定以哪一个字段作为标准来排列,这个这顶标准就是key。
举个例子:
1
2
3
4
5
6listA = [3, 6, 1, 0, 10, 8, 9] #这个列表就是单字段,排序就是单纯按照数字大小排序
print(sorted(listA))
[0, 1, 3, 6, 8, 9, 10]
listC=[('e', 4), ('o', 2), ('!', 5), ('v', 3), ('l', 1)] #这个列表是多字段
print(sorted(listC, key=lambda x: x[1])) #指定按照多字段里第二个元素,即数字的大小进行排序
[('l', 1), ('o', 2), ('v', 3), ('e', 4), ('!', 5)]
x:x[]字母可以随意修改,排序方式按照中括号[]里面的维度进行排序,[0]按照第一维排序,[2]按照第三维排序
参考资料
https://stackoverflow.com/questions/7851077/how-to-return-index-of-a-sorted-list
https://stackoverflow.com/questions/16310015/what-does-this-mean-key-lambda-x-x1
https://blog.csdn.net/u010758410/article/details/79737498


