试题内容
- Mysql的
bin-log有几种形式?分析其特点Statement Level模式:1
2
3简介:每一条会修改数据的sql都会记录到master的bin-log中。Slave在复制的时候sql线程会解析成和原来master端执行过的相同语句来执行。
优点:不需要记录每一行数据的变化,减少bin-log的日志量,节约IO,提高性能。因为他只记录在master上所执行语句的细节,以及执行语句时候的上下文的信息。
缺点:很多新功能的加入在复制的时候容易导致出现问题。Row Level模式:1
2
3简介:日志中会记录成每一行数据被修改的模式,然后再slave 端在对相同的数据进行修改。
优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息。仅仅只需要记录那一条记录被修改了。所以row level的日志内容会非常清楚记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特点情况下的存储过程,或function 以及triggeer的调用和触发无法被正确复制的问题。
缺点:所有执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,可能会产生大量的日志。
Mixed(前两种的混合模式):
1
根据执行的每一条具体的sql语句来区分对待记录日志的形式,即Mysql决定什么时候写statement格式的,什么时候写row格式的binlog。;
- 如何在线正确清理MySQL的binlog?
手动删除方法如下:1
2
3
4
5
6#首先查看主从库正在使用的binlog文件名称
show master(slave) status\G
#删除之前一定要备份
purge master logs before'2017-09-01 00:00:00';
#删除指定时间前的日志
purge master logs to'mysql-bin.000001';
自动删除的方法如下:
1
2
3
4#通过设置binlog的过期时间让系统自动删除日志
#查看过期时间与设置过期时间
show variables like 'expire_logs_days';
set global expire_logs_days = 30;
binlog记录了数据中的数据变动,便于对数据的基于时间点和基于位置的恢复。但是也要定时清理,不然越来越大。
- 简述MySQL主从复制原理及配置主从的完整步骤。
MySQL主从是一个异步过程(网络条件上佳的话,同步效果几乎是实时),原理就是从库得到主库的binlog,然后执行这个binlog的内容,达到两边数据库数据一致的目的。具体工作步骤如下: - 主mysql服务器将数据库更新记录到binlog中,使用自己的
log dump线程将binlog先读取然后加锁,再发送到从库,在从库当读取完成,甚至在发动给从节点之前,锁会被释放; - 当从库上执行
start slave命令之后,从节点会创建一个I/O线程用来连接主节点,请求主库中更新的binlog。I/O线程接收到主节点binlog dump进程发来的更新之后,保存在本地relay log中。 - 从库此时还有一个SQL线程,它负责读取
relay log中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。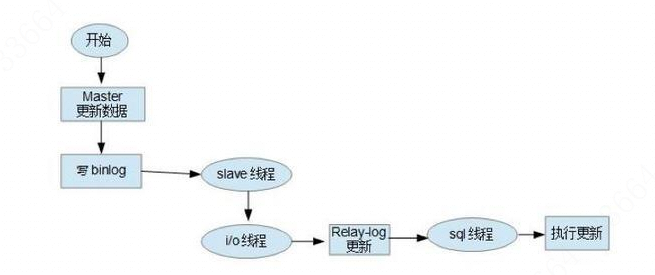
切记!在从库上使用show slave status\G;看到结果里的Slave_IO_Running:Yes和Slave_SQL_Running:Yes,才算是同步成功,两个YES缺一不可。
注意!MySQL只读实例的Binlog日志是没有记录更新信息的,所以它的Binlog无法使用。
如何理解MySQL里最大连接数和请求数之间的关系
假设某个数据库的最大连接数是1000,并不是指最多只能支持1000个访问,因为数据库与应用之间肯定会隔着中间件,这个中间件的连接池会管理链接,一般如果代码写的好、事物控制得当,一个事物完成连接会被连接池收回重复利用,所以不是说一个用户登录你的系统或网站就一直占用着,一个连接也可以包含多次请求。MySQL出现IOPS过高,应该如何处理?
IOPS (Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数。IOPS是指存储每秒可接受多少次主机发出的访问,主机的一次IO需要多次访问存储才可以完成。IOPS过高比较普遍的原因是实例内存满足不了缓存数据或排序等需要,导致产生大量的物理IO或者是查询执行效率低,扫描过多数据行。Sort_Buffer_Size是什么参数?设置它对服务器性能有何影响?
Sort_Buffer_Size是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。Sort_Buffer_Size并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。Sort_Buffer_Size超过256KB的时候,MySQL就会使用mmap()而不是malloc()来进行内存分配,导致性能损耗、效率降低。
如果列长度大于max_length_for_sort_data的参数值的话,iowait会增加, 响应时间明显变长。此时通过show processlist查看,发现有很多session在处理sort操作,此时需要适当调大max_length_for_sort_data的参数值。
- 如何从MySQL全库备份中恢复某个库和某张表
主要用到的参数是–one-database简写-o的参数,举个例子:1
2
3
4全库备份
[root@HE1 ~]# mysqldump -uroot -p --single-transaction -A --master-data=2 >dump.sql
只还原erp库的内容
[root@HE1 ~]# mysql -uroot -pMANAGER erp --one-database <dump.sql
从全库备份中抽取出t表的表结构:
1
sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `t`/!d;q' dump.sql
从全库备份中抽取出t表的内容:
1
grep'INSERT INTO `t`' dump.sql
- 随意举出一次解决Mysql故障的事例
Mysql反应很慢,发现服务器CPU飙升,出现僵尸进程但是连接数并不高,show processlist发现有大量的unauthenticated user。通过更改配置文件/etc/my.cnf里的在[mysqld]那一栏中添加skip-name-resolve,然后重启mysql即可解决。
注意! skip-name-resolve可以禁用dns解析,但是,这样不能在mysql的授权表中使用主机名了,只能使用IP。以前创建mysql用户是若用的是localhost现在则需要用127.0.0.1来代替在grant语句中执行一下添加该用户。
当然CPU飙升还有其他情况:查询以及大批量的插入或者是网络状态突然断了,导致一个请求服务器只接受到一半…
你们数据库是否支持emoji表情,如果不支持,如何操作?
如果是utf8字符集的话,需要升级至utf8_mb4方可支持。mysqldump备份时,–master-data选项的作用是什么?还用过其他的参数么?
--master-data选项的作用就是将二进制的信息写入到输出文件中,即写入备份的sql文件中。--master-data=2表示在dump过程中记录主库的binlog和pos点,并在dump文件中注释掉这一行;--master-data=1表示在dump过程中记录主库的binlog和pos点,并在dump文件中不注释掉这一行,即恢复时会执行;--dump-slave=2表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,记录当时主库的binlog和pos点,并在dump文件中注释掉这一行;--dump-slave=1表示在dump过程中,在从库dump,mysqldump进程也要在从库执行,记录当时主库的binlog和pos点,并在dump文件中不注释掉这一行;
注意!在从库上执行备份时,即–dump-slave=2,这时整个dump过程都是stop io_thread的状态
加了--single-transaction就能保证innodb的数据是完全一致的,而myisam引擎无法保证(因为myisam压根就不支持事务),要保证myisam引擎数据一致必须加--lock-all-tables。
- 什么是数据库事务,事务有哪些特性?
一个数据库事务通常包含对数据库进行读或写的一个操作序列。它的存在包含有以下两个目的:它的特性如下:1
2为数据库操作提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。1
2
3
4原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
事务的原子性与一致性缺一不可。
- 数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
语句如下:1
select distinct name from student
注意!单独的distinct只能放在开头,否则就报语法错误。
select * from table limit 2,1;、select * from table limit 2 offset 1;和select * from employee limit 3;这三个sql有什么区别?
第一个sql含义是跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据;
第二个sql含义是从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条;
第三个sql含义是返回前三行;
参考资料
https://www.cnblogs.com/wajika/p/6718552.html
https://www.hollischuang.com/archives/898
https://zhuanlan.zhihu.com/p/50597960
https://segmentfault.com/a/1190000008663001
https://segmentfault.com/a/1190000000616820
http://seanlook.com/2014/12/05/mysql_mysqldump_options_examples/

