目前大环境感觉不好,哪哪都是裁人的消息,所以这个时候更是要摆正心态、沉淀自己。
今年我个人的小目标是:Hadoop+k8s+python开发,这次就先写Hadoop的部署过程,可能会有一些名词看不懂,等下一篇再说名词解释。
先说环境:
1
2192.168.1.86 Master 华为云Centos7.5
192.168.1.165 Salve 华为云Centos7.5
为了高可用,还要部署zookeeper来监视节点心跳情况,我这个例子里没有,如果有需要可以单独部署。
所有机器都要操作
本段过程是所有的服务器都要一起操作的!
先
yum update -y,在等待的时候,我们就新开一个窗口,wget http://apache.01link.hk/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz下载3.1.2版本的hadoop,下载完毕后,解压缩hadoop-3.1.2.tar.gz到/opt下,然后把hadoop-3.1.2改名叫hadoop。在
yum update -y完成之后,我们还要yum install java-1.8.0-openjdk* -y,安装完毕之后,执行java -version确认已经安装java 1.8成功。在
/etc/hosts文件里添加:1
2192.168.1.86 master
192.168.1.165 slave修改配置文件,hadoop所有的配置文件都在
/opt/hadoop/etc/hadoop路径下。
先修改hadoop-env.sh,添加一句export JAVA_HOME=/usr,因为我们直接用yum安装的,java默认就会安装到/usr/bin/java。所以这里写/usr即可,如果是另外方法安装需要写具体的路径而且要修改/etc/profile和source /etc/profile。
在core-site.xml里的configuration里添加如下内容:
1
2
3
4
5
6
7
8
9
10<!-- 指定hadoop运行时产生文件的存储目录,可以指定自己熟悉的目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 指定hadoop使用的文件系统,HDFS的老大NameNode的地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
在hdfs-site.xml里的configuration里添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 <!-- 指定HDFS副本数量,默认3 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
<!-- 如果不加这句话,50070端口打不开 -->
</property>
在mapred-site.xml里的configuration里添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13<!-- 指定mapred运行时的框架:yarn,默认local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop/var</value>
</property>
在yarn-site.xml里的configuration里添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50 <property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
- 把workers这个文件里的localhost替换成slave,2.X版本hadoop里的workers文件叫slaves。
至此,所有机器操作的部分完毕,要确认两边的内容必须保持一致,不然启动的时候就会出现优先级出错的故障。
只有Master操作
以下操作只有master操作!
由于Master是namenode,slave是datanode,现在就需要对namenode进行一个初始化的操作,即是hdfs的一个初始化。
进入/opt/hadoop/bin里,执行./hadoop namenode -format ,格式化一个新的分布式文件系统,如果不报错那就说明成功。完毕之后,可以去/opt/hadoop/dfs/name这个目录下发现多了一个current文件夹。
配置普通用户免密码登录
至此整个部署过程就完毕了,如果是root用户就可以直接去/opt/hadoop/hadoop-2.8.0/sbin下执行./start-all.sh了,但是为了安全,我们不要用root用户去启动hadoop,而是用普通用户去启动它。
于是我们先在两台机器上adduser hadoop,这里不设置密码。然后chown -R /opt/hadoop,把整个hadoop文件夹的权限都给hadoop用户。
然后执行ssh-keygen -t rsa,一顿回车之后发现在/home/hadoop/.ssh下有了id_rsa和id_rsa.pub这俩文件。这俩就是root用户的ssh公钥和私钥文件,su hadoop切换到hadoop用户上,同样的操作一遍,获取到hadoop用户的ssh公钥和私钥文件。
master和slave都在/home/hadoop/.ssh下新建一个文件叫authorized_keys,并且互相复制对方的hadoop的id_rsa.pub到自己的authorized_keys里,然后再复制自己的root的id_rsa.pub到自己的authorized_keys里。
修改authorized_keys的权限是600,此时无论是master还是salve的hadoop用户都应该可以无密码登录自己和对方,如图:
启动Hadoop
当前用户是hadoop,在master机器上执行/opt/hadoop/sbin/start-all.sh即启动hadoop,如图: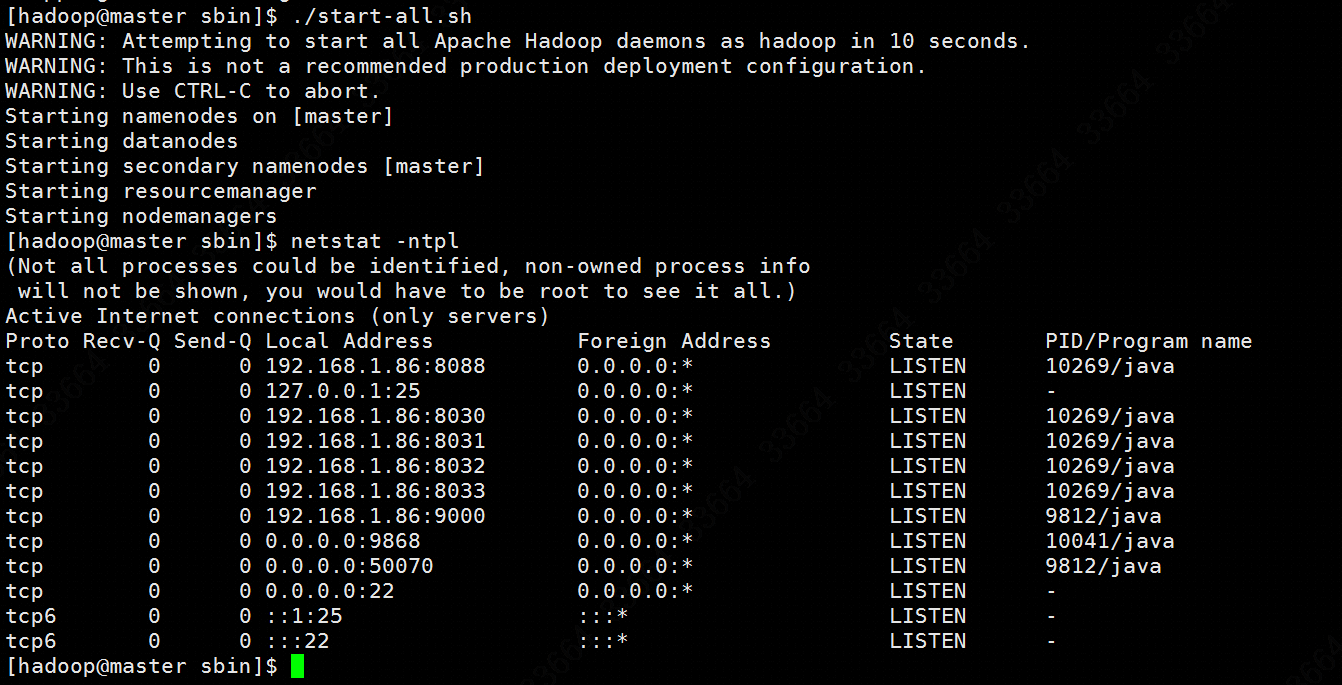
此时在slave机器上会看到有两个进程启动:
1
2hadoop 13552 1 2 10:35 ? 00:00:03 /usr//bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/opt/hadoop/logs -Dyarn.log.file=hadoop-hadoop-datanode-slave.log -Dyarn.home.dir=/opt/hadoop -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop/lib/native -Dhadoop.log.dir=/opt/hadoop/logs -Dhadoop.log.file=hadoop-hadoop-datanode-slave.log -Dhadoop.home.dir=/opt/hadoop -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode
hadoop 13670 1 3 10:35 ? 00:00:04 /usr//bin/java -Dproc_nodemanager -Djava.net.preferIPv4Stack=true -Dyarn.log.dir=/opt/hadoop/logs -Dyarn.log.file=hadoop-hadoop-nodemanager-slave.log -Dyarn.home.dir=/opt/hadoop -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop/lib/native -Dhadoop.log.dir=/opt/hadoop/logs -Dhadoop.log.file=hadoop-hadoop-nodemanager-slave.log -Dhadoop.home.dir=/opt/hadoop -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.yarn.server.nodemanager.NodeManager
或者使用jps命令在双方机器上查看启动的进程名:
1
2
3
4
5[root@slave hadoop]# jps
13552 DataNode
13670 NodeManager
1543 WrapperSimpleApp
13790 Jps
在华为云的安全组里对这俩服务器打开50070端口和8088的公网访问端口,然后在浏览器里输入http://master公网IP:50070即可查看效果: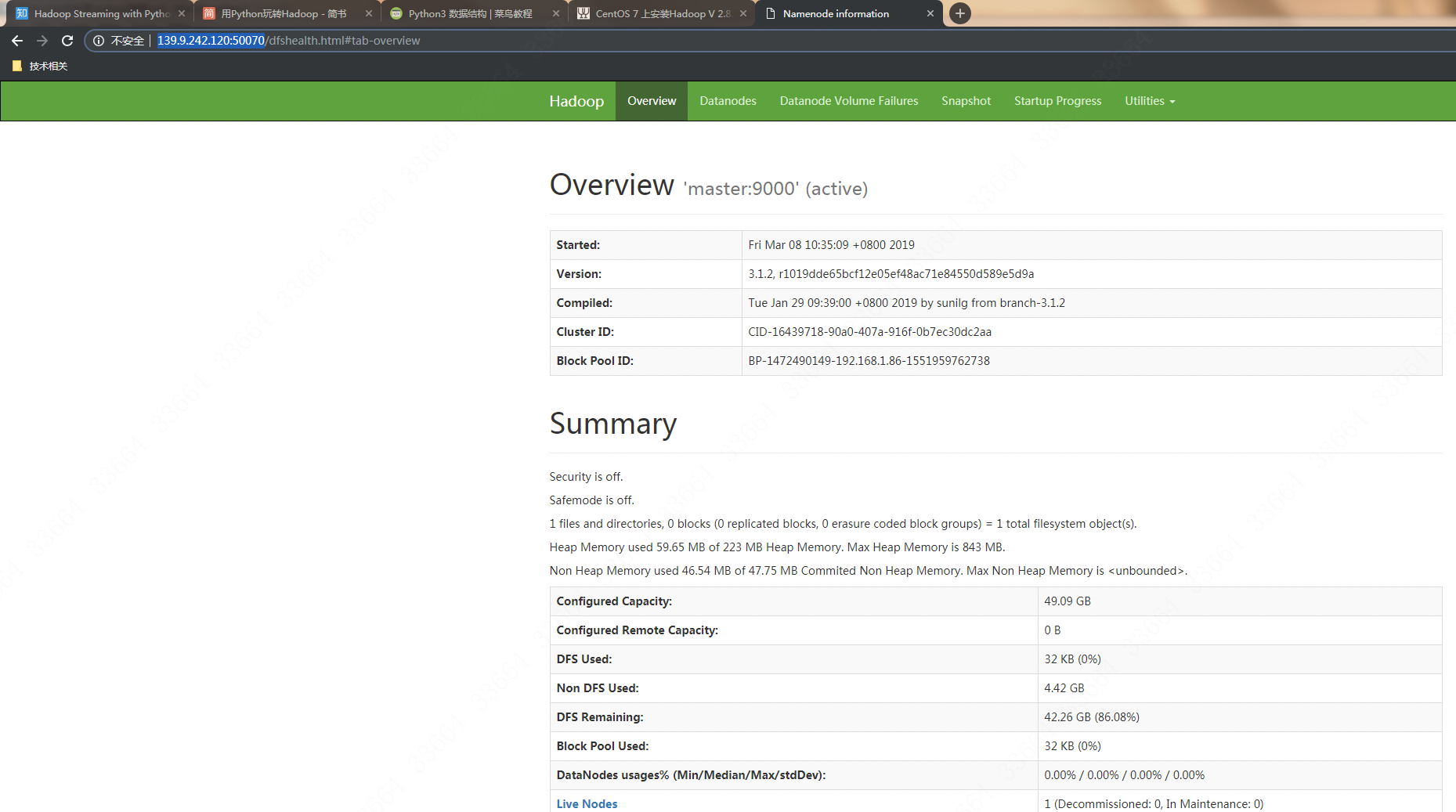
而输入http://master公网IP:8088就会看到cluster页面: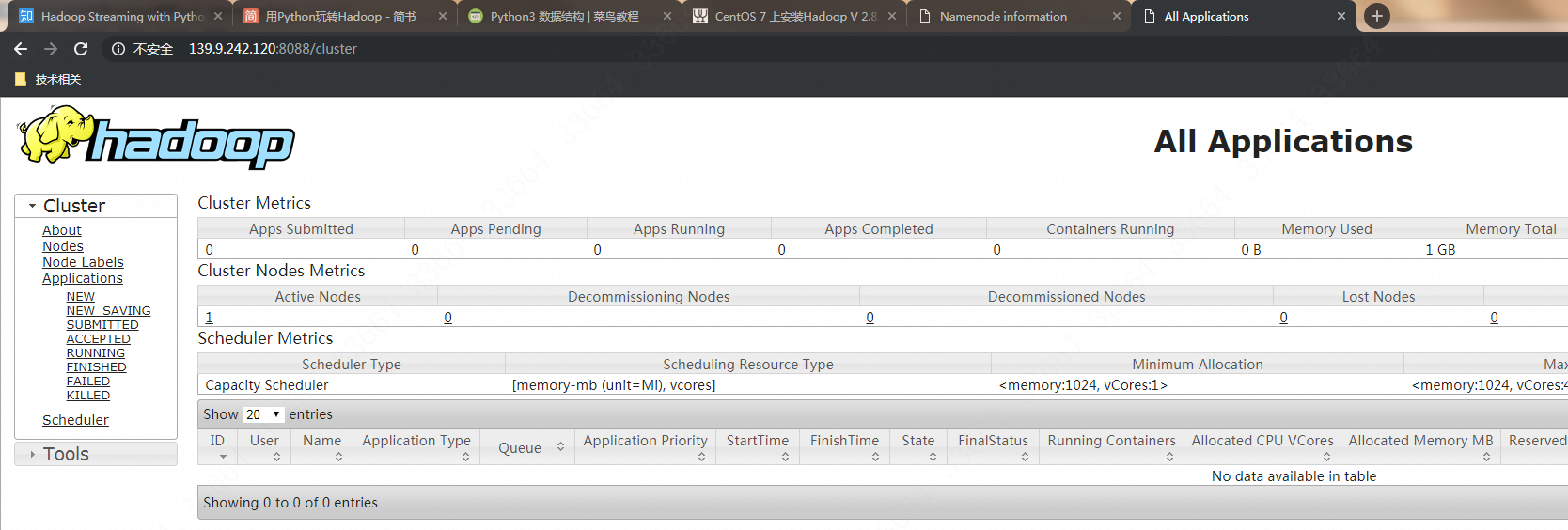
如果要关闭,就在master执行/opt/hadoop/sbin/stop-all.sh,至此一个简单的hadoop集群搭建和启动完毕。
参考资料
https://www.cnblogs.com/charlesblc/p/6030008.html
https://blog.wuwii.com/linux-hadoop.html

