正文
我有一个数据库,每天都要从公司的数据库同步一些数据。但是这样就遇到一个问题:希望先判断数据是否相同,如果相同就跳过,不同就更新或者新增。那么比较笨的方法就是先取到要插入的数据,判断一下select count(*) from 表 where XXX="要插入的数据的某一列",如果返回的值是0就是insert,如果返回的不是0那就update。
但是这样的方法比较low,而且还有一定的性能隐患,其实这个需求可以用一句MySQL语句来实现,但是前提是该表里有唯一键。
举个例子,比如我有一个这样的表,表里面记录了一些球员的基础信息,如图:
现在我要插入一条如下的语句:
1
insert into players(name,team,number) values ("james","cavaliers","23")
可见新插的数据里,name列和number列一致,但是team不一致,那么要达到目标可以使用replace into语句,但是需要表里有UNIQUE KEY。什么是UNIQUE KEY(唯一键)这个是MySQL的基础知识,Google一下一大把,这里不多说了。我先alter table players ADD unique (name);如图:
这样就指定了name是唯一键,即球员的名称不可以出现重复,此时使用:
1
replace into players(name,team,number) values ("james","cavaliers","23");
效果如图: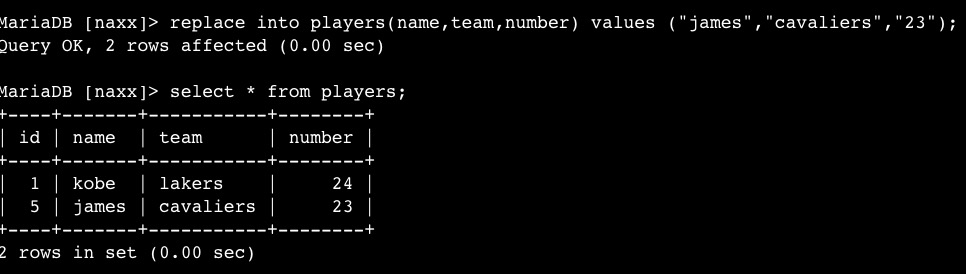
而且replace into还可以是作为insert into使用,如果name这一列是新的,就会直接insert。
但是这个时候不可以用insert ingore,因为是name为UNIQUE KEY,那么新插入的语句name是相同的,则不会插入,反而会爆出一个warning,使用show warnnings一看,提示name重复了,插入失败,但是语句是执行OK的,不会报error。如图: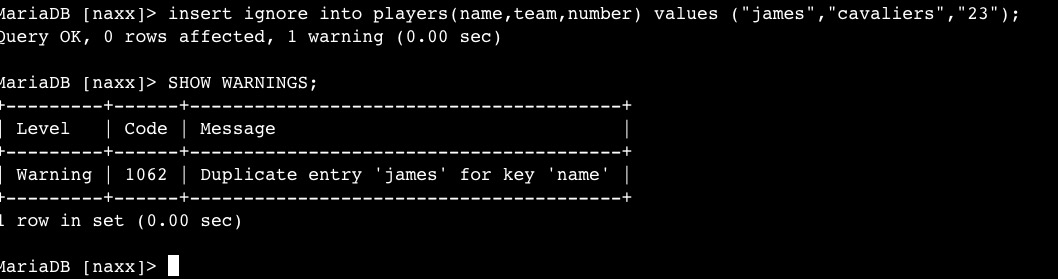
参考资料
https://blog.csdn.net/t894690230/article/details/77996355
https://blog.csdn.net/BuptZhengChaoJie/article/details/50992923
https://www.yiibai.com/mysql/unique-constraint.html

