准备工作
Odps是阿里巴巴集团的一个大数据解决方案,现在改名叫MaxCompute了,但是为了方便还是叫odps居多。我现在的需求就是需要把数据从ODPS同步到MySQL里来,那么首先需要分别在odps和mysql上创建两个两个结构一样的表。
mysql对应的建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13CREATE TABLE `naxxramas_mactasks` (
`id` varchar(200) NOT NULL COMMENT '主键',
`rule_case_id` int(11) DEFAULT NULL COMMENT '关联的case表ID',
`rule_name` varchar(100) DEFAULT NULL COMMENT '规则名称',
`app_name` varchar(50) DEFAULT NULL COMMENT '关联应用名称',
`product_name` varchar(50) DEFAULT NULL COMMENT '域名',
`exec_type` varchar(20) DEFAULT NULL COMMENT 'ODPS表示离线核对,RTT表示准实时核对',
`result` mediumtext COMMENT '执行结果',
`rules` varchar(2000) DEFAULT NULL COMMENT '内部规则',
`status` int(11) DEFAULT NULL COMMENT '执行状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='mac稽核平台的规则对应的任务执行失败的信息'
;
odps也创建表,各字段名以及类型情况如下: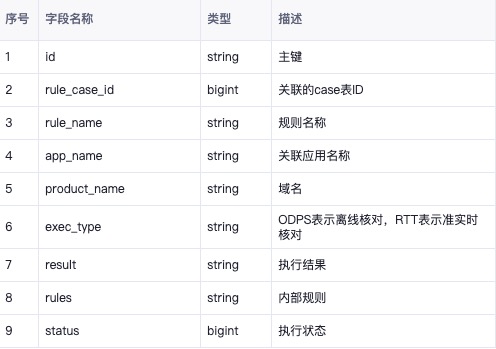
这里温馨提示,为了以后的方便,我强烈建议一定要把两个表的列名和列属性设置的完全一致,这样避免很多写不进去或者写进很多脏数据的问题。这是踩坑者的经验之谈!
我之前同步他俩是用自己写的一个python3的脚本,但是遇到大数据量的脚本同步跟MySQL的交互就太频繁了,导致屡屡出现ConnectionResetError: [Errno 104] Connection reset by peer的错误,就想起来干脆都迁移到dataX里同步吧,省事还正规。
安装DataX
DataX是阿里巴巴集团的一个数据同步工具,可以实现实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。它需要以下环境:JAVA1.8+,python2和maven3.x。安装方法如下:
1
2
3
4
5
6
7sudo yum -y install java-1.8.0-openjdk-devel.x86_64
sudo yum -y install maven
sudo mkdir -p /opt/dataX
sudo chown admin:admin -R /opt/dataX
cd /opt/dataX
sudo wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar -zxvf datax.tar.gz
从上可见我这个账号是admin并不是root,那么安装了java就不用去source /etc/profile那一步了,因为普通用户source不进去,你sudo source会爆错sudo: source: command not found的。不是不用担心,不耽误正常使用。maven也一样,yum安装后,就可以了,不用去更改系统变量。效果如图:
首先先到bin目录里,由于我是要从odps数据同步到mysql里,那么执行python datax.py -r odpsreader -w mysqlwriter,-r就是源头,-w就是目标,这里要注意,源头和目标写法要跟plugin文件夹的写法一样,区别大小写,如图:
然后就会出现一个json的例子,你就需要新建一个文件,比如叫odps2mysql.json,按照这个demo一一填写具体的内容就好:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61[admin@naxxramas011158137063.na61 /opt/dataX/datax/bin]
$python datax.py -r odpsreader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the odpsreader document:
https://github.com/alibaba/DataX/blob/master/odpsreader/doc/odpsreader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessId": "",
"accessKey": "",
"column": [],
"odpsServer": "",
"packageAuthorizedProject": "",
"partition": [],
"project": "",
"splitMode": "",
"table": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
具体每一个key的含义可以去看文档,odps的源头字段文档是https://github.com/alibaba/DataX/blob/master/odpsreader/doc/odpsreader.md ,mysql的目标字段文档是https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md。 其他的数据库也可以在dataX的github地址在这里:https://github.com/alibaba/DataX/blob/master/userGuid.md 里找到。
保存好json文件,然后python datax.py odps2mysql.json就可以启动了,如图:
注意一下,如果你的数据库条非常多,比如我这个例子是42万条记录,那么MySQL默认的写入batchSize是1024,很有可能会把1G的内存打挂,所以建议这个值要根据实际情况而来。
如果你启动出现了com.alibaba.fastjson.JSONObject cannot be cast to java.lang.String的错误,如图:
那么只有一个可能:你的json文件格式不正确,请去重新检查再来过。
如果你的datax作业没有任务错误却直接退出了,如图: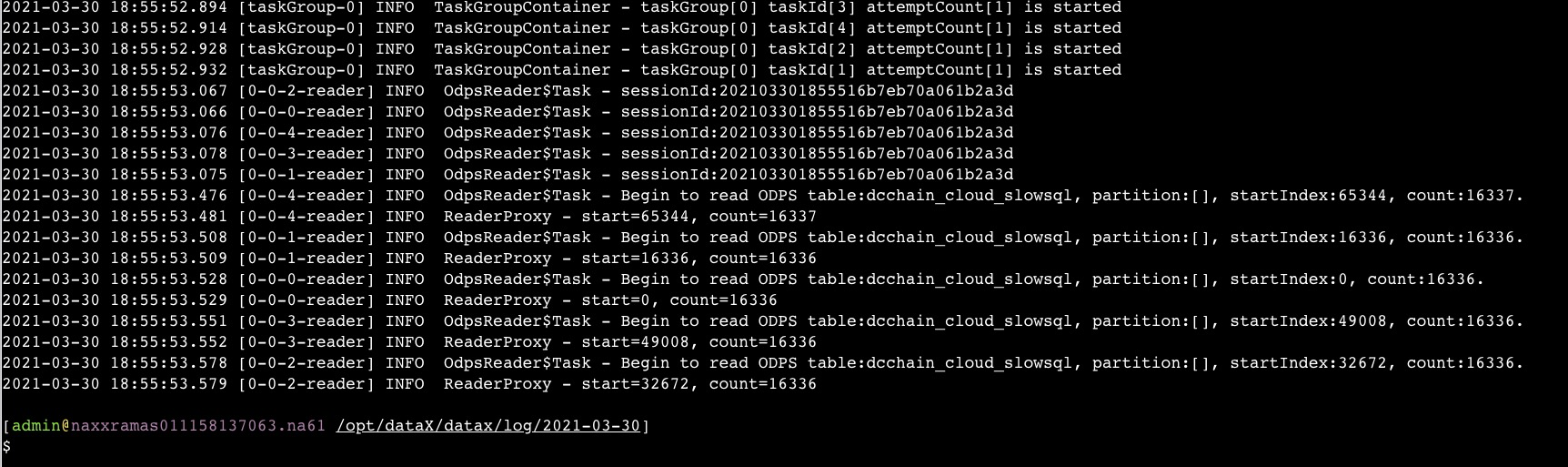
那么请调小json文件里的channel值,比如改成2或者1,这样就能跑起来了。

