背景说明
数据中心的核心功能是提供数据聚合的服务,什么叫数据聚合,简而言之就是把业务想要的数据从具体的数据提供方应用里面去取出来,封装好之后统一返回给业务方。为了方便理解,我用一次最简单的调用过程来进行说明:
以上例子中,伙拼作为1个业务方,想要获取商品列表,并且补充商品中的基本信息和一些标签、营销等信息,那么这个时候,伙拼会根据约定携带参数向数据中心发起一个RPC请求。数据中心接收到请求之后,第一次发起RPC调用,从主数据源(数据源:是具体数据提供方的统称)获取到伙拼需要的商品,然后再并发的再向各个其他数据源发起请求去取商品的属性信息,最后把各个数据源的返回结果合并返回给伙拼业务方。
纵观整个过程,“数据中心”并不自己产生数据,数据都是从其他的应用通过网络请求去取的,数据中心充当的是一个代理和搬运工的角色,去帮业务方把数据拿到并组装好。通过这种方式,制定一套数据中心自己的数据接入和取数规范,以此来减少业务方的硬编码,大大提升数据扩展能力和业务快速迭代的能力。
明确性能问题
数据中心是一个中心化的应用,需要扛各个业务方的调用,而中心化的应用性能瓶颈很明显:能提供的最大QPS依赖于应用本身集群机器数量的大小。在服务器资源有限的情况下,数据中心出现了服务器集群load高的问题,而服务器load一旦偏高,就会导致机器的rt抖动,从而影响前台业务的稳定性。在优化前日常load峰值已经飙高到3.1+,对于普通配置的4核机器,这个load算是比较高的了: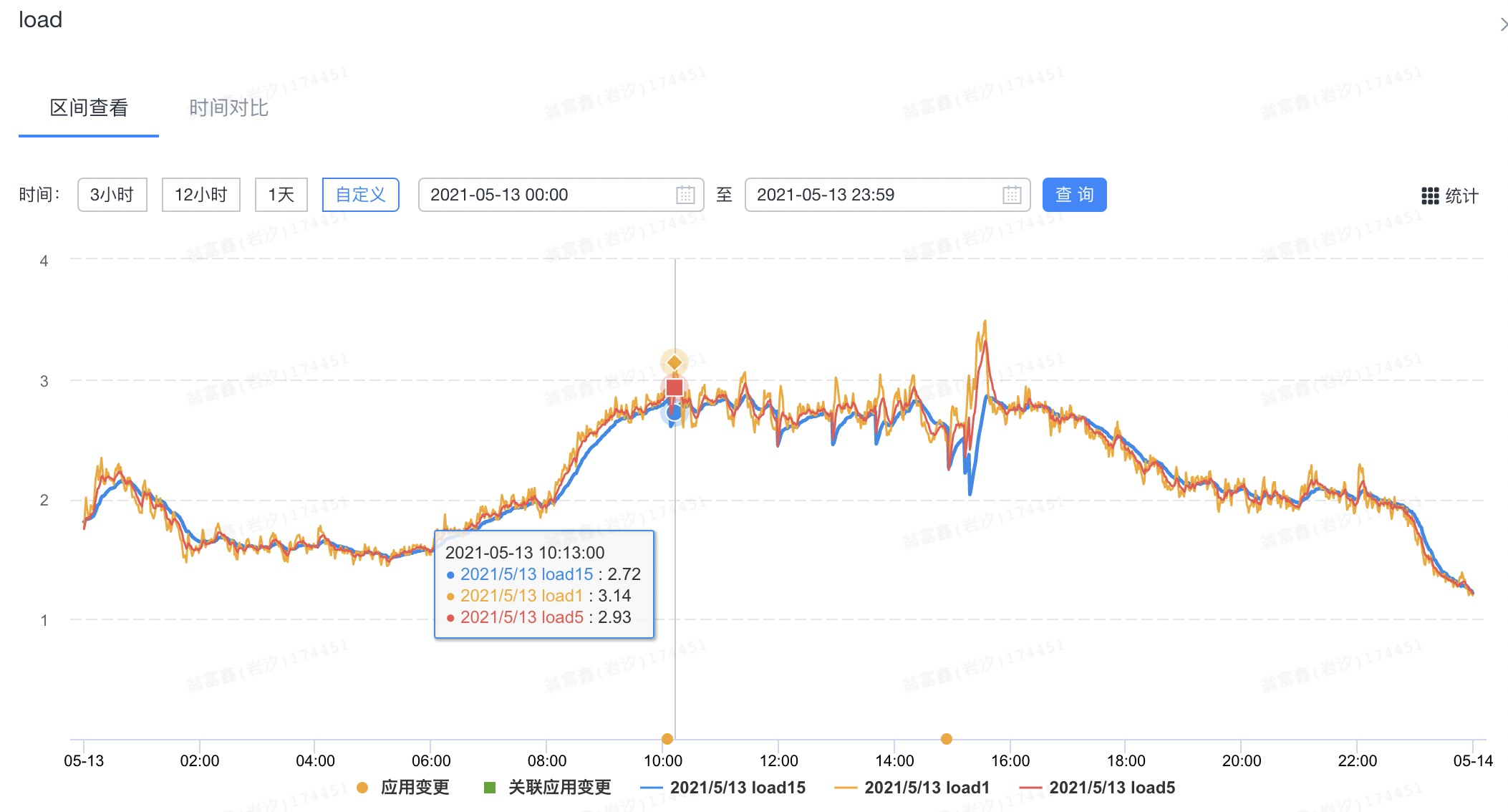
而load高可能是流量过高导致服务器负载高,也有可能是自身有性能瓶颈,这里我们抱着优化自身性能的初心,从自身的机器着手尝试去解决问题。
使用arthas进行初步分析
要分析应用的热点代码,可以根据方法调用栈采样的方式来分析,而“火焰图”恰好就是干这个的,这里可以直接使用集团现成的工具:arthas。于是,我在线上找了运行了好几天的几台load高的机器,通过arthas的火焰图采样,发现这几台load高机器的火焰图有一些共性,大致都长如下的样子: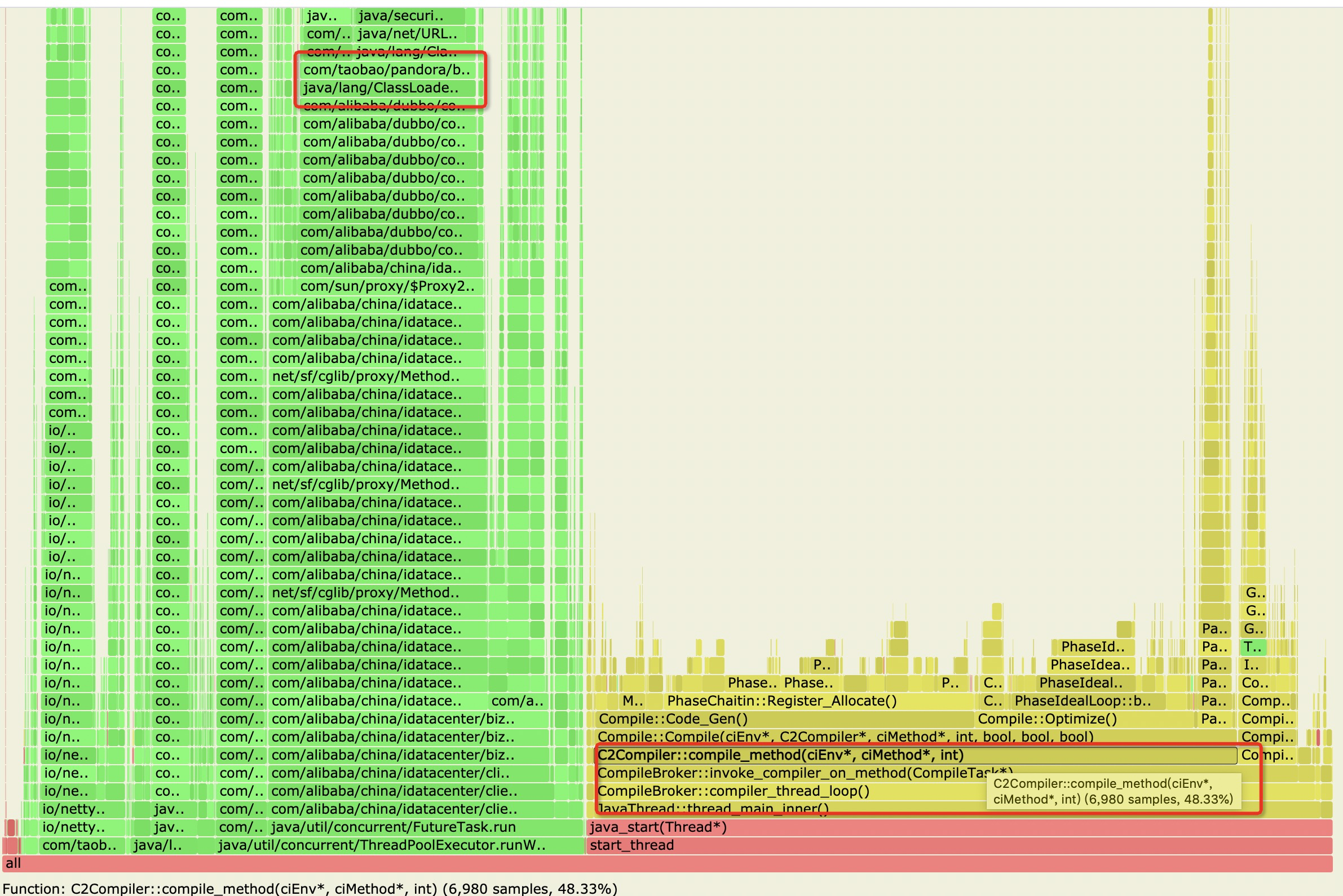
根据得到的火焰图结果,去找比较宽的函数,可以简单理解函数越宽,其占的CPU越高,具体怎么看火焰图我在文章后面会附链接。通过以上的火焰图可以比较明显的看到两个问题,我在图中已经圈出:
1、C2Compiler::compile_method xxx 占了48.33%的采样结果,C2是一个JIT编译器
2、ClassLoader.loadClass 占了9.2%的采样结果
基于这两个问题,脑子里应该有两个疑问:1、JIT对性能的影响应该是在机器刚启动时影响较大,为什么机器运行了这么久,jit还这么活跃以致于占了这么多的采样?2、为什么ClassLoader也这么活跃,采样占比这么高?
疑问排查
我先看的第一个问题,由于JIT编译会使用到CodeCache,怀疑是不是CodeCache的空间不够?查看Sunfire监控,发现CodeCache利用率还算处于正常水位: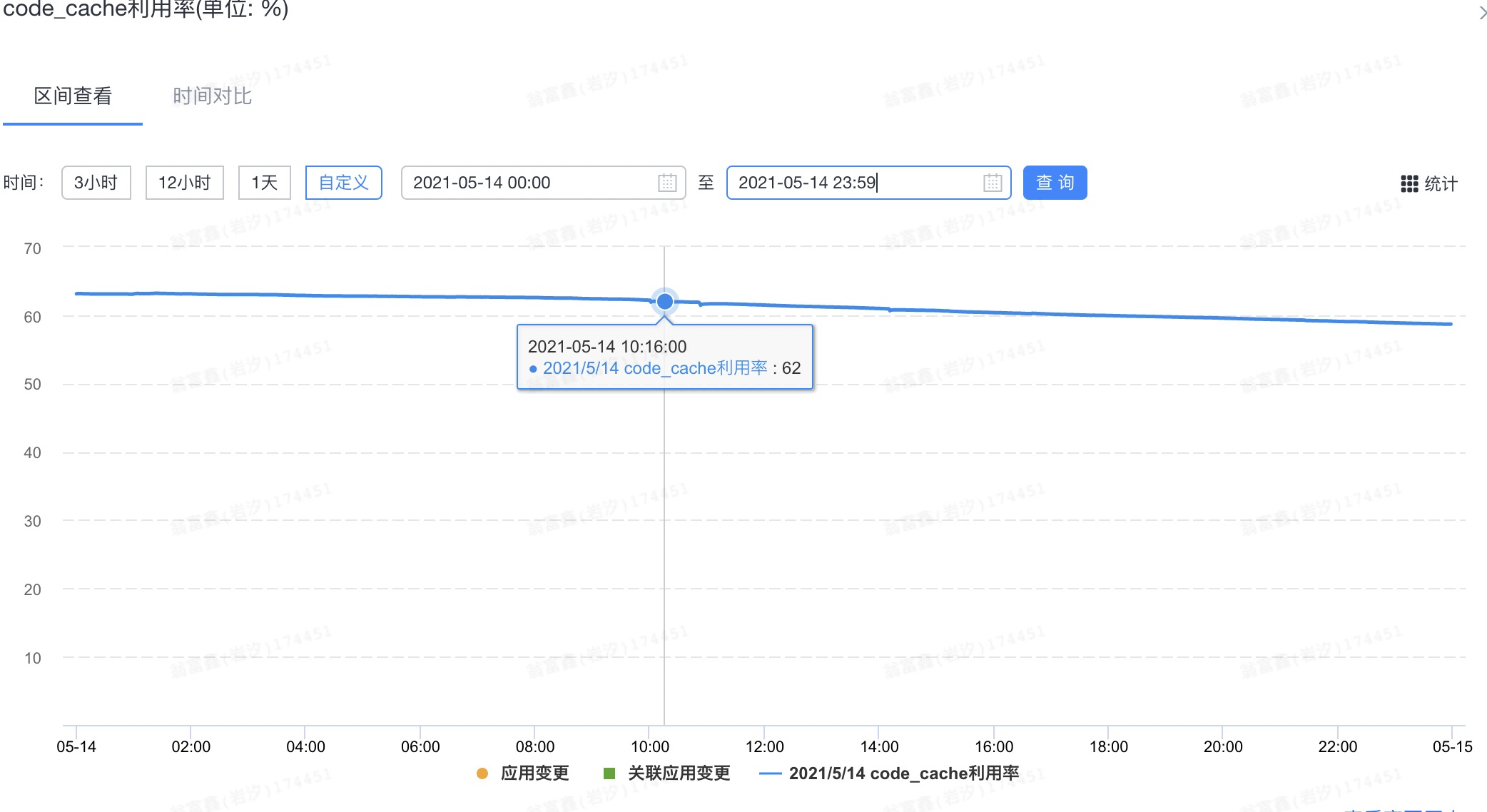
暂时排除了CodeCache空间不足的原因。而且由于我们应用使用的是Java8,默认会开启分层编译,JVM会自适应的去调整使用的编译器,但现在线上jit还这么活跃,真有点让人摸不着头脑。于是我接下来在预发去尝试了修改编译器线程数量、增大CodeCache、甚至关闭分层编译等一系列操作,但最后都没发现有太多的性能提升,甚至在关闭分层编译之后机器启动后的几分钟内load飙到好几十: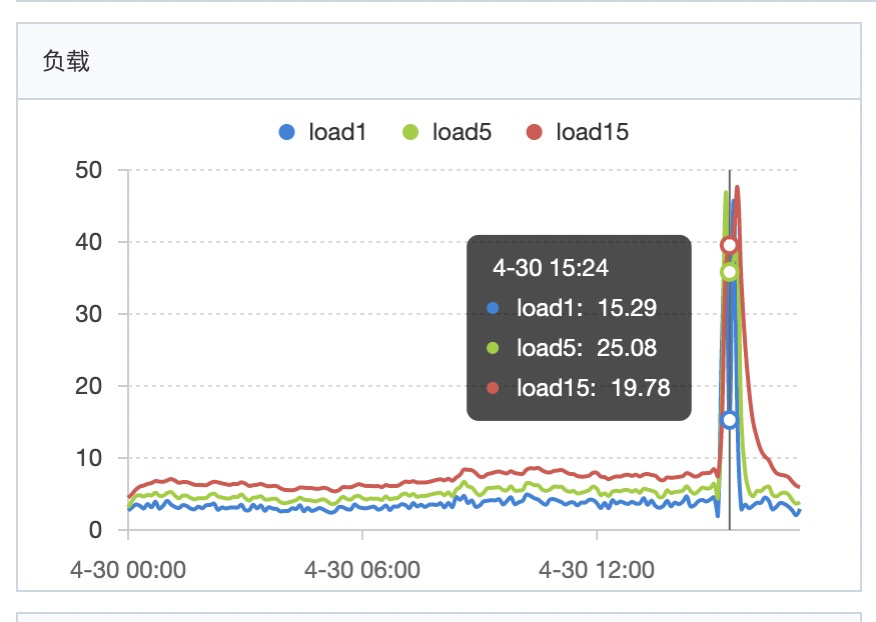
其实JIT这块对于应用开发的工程师来说,是相对黑盒的,在没经过大量验证的情况下,也不敢轻易修改默认的JIT配置,所以关于JIT影响性能这块,没有得到太多的有效结论。
只能马上转头看第二个问题,为什么ClassLoader这么活跃?点击火焰图的函数,可以看到详情: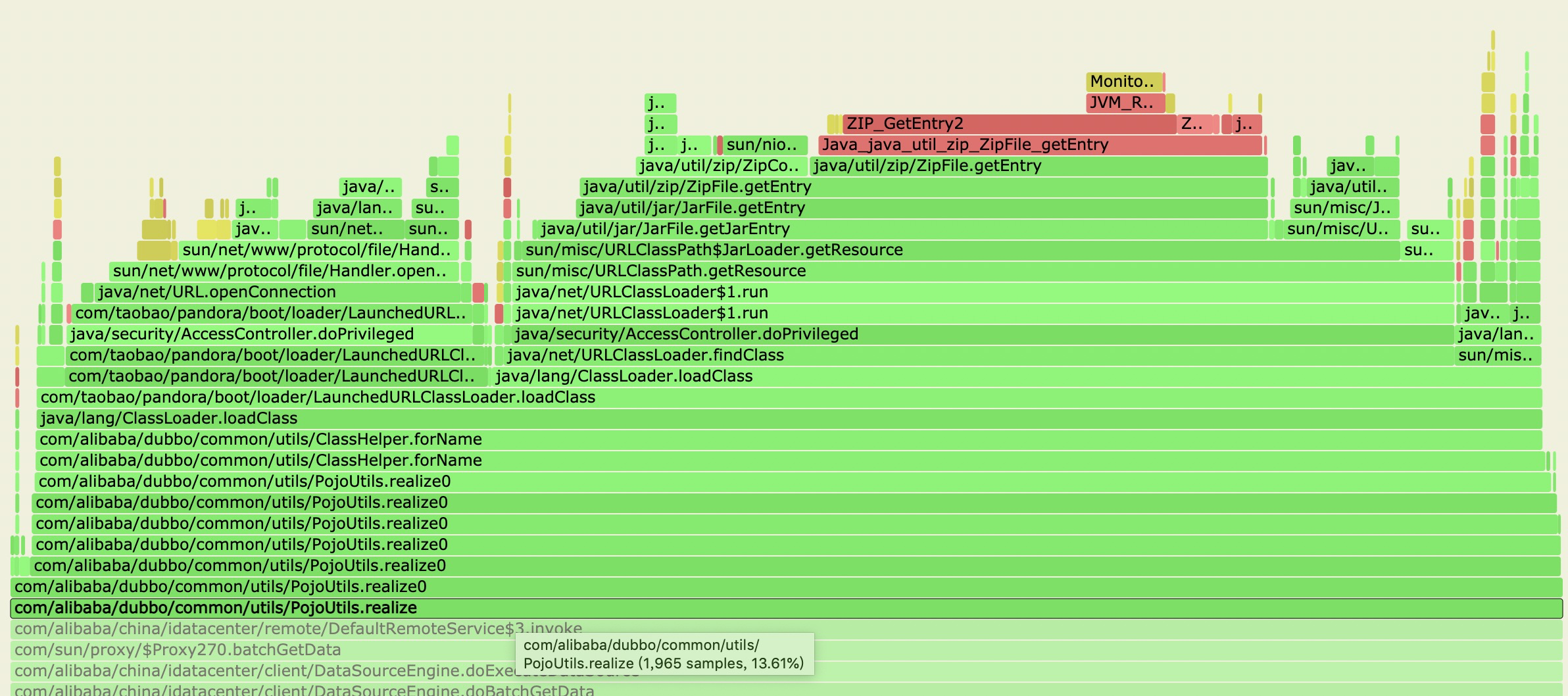
ClassLoader#loadClass往下找是具体的调用来源,可以发现ClassLoader的调用其实是来自于com.alibaba.dubbo.common.utils.PojoUtils#realize这个方法,这个方法是干嘛的?我截取了该方法唯一在数据中心的调用代码,如下:
1 | bean = Proxy.newProxyInstance(type.getClassLoader(), new Class[]{type}, new InvocationHandler() { |
这里简单介绍一下,由于数据中心制定了一个RPC接口规范,数据源接入需要在自己的应用里面实现我们的规范接口,而在数据中心发起调用的时候是通过泛化调用的方式来进行调用的,以此来实现扩展性。数据中心定制的核心规范接口如下:
1 | import com.alibaba.china.idc.common.model.Context; |
其中com.alibaba.china.idc.common.model.Result是数据中心定义的一个Model,Map用来存放数据源返回的数据。泛化调用返回的结果都会被处理成HashMap类型的数据,如下是我模拟的一个泛化调用返回对象toJSONString的结果,value结果里面如果是一个自定义的Java对象,则会添加一个class字段来标示当前的类型: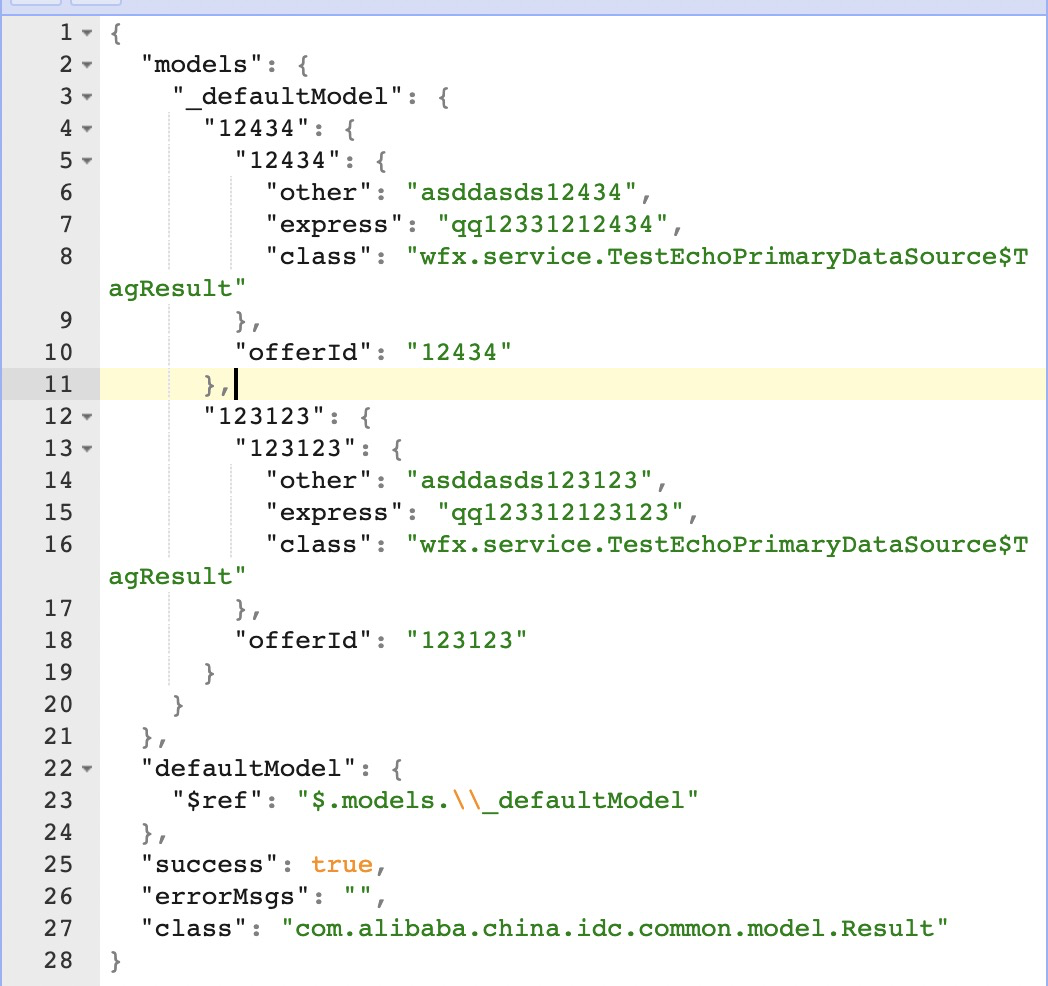
关键点就在这里,这个PojoUtils#realize实际上是将泛化调用的返回结果Map类型转化为数据中心自定义的Java类型,里面会递归的读取class字段里面的内容,并尝试通过反射把HashMap通过转化为对应的类型,如下是这个工具类的核心源码部分:
在以上的case中,PojoUtils会首先通过读取到com.alibaba.china.idc.model.Result这个字符串,并通过反射生成一个对象,这没问题,因为这个Model是数据中心定义的。然后会去读到wfx.service.TestEchoPromaryDataSourcre$TagResult这个字符串,并尝试通过反射创建一个对应的对象,这里问题就来了,数据中心并没有这个类的定义。
所以,现在问题大概就清楚了:业务方在数据中心规范的接口返回Map中,塞了自己的定义的Model,而数据中心并没有导入他们的二方包!因此会陷入ClassLoader一直去加载这个类,但是每次都加载不到的这种死循环中。而且需要注意的是,ClassLoader加载类的方法块里面,有一段同步代码块: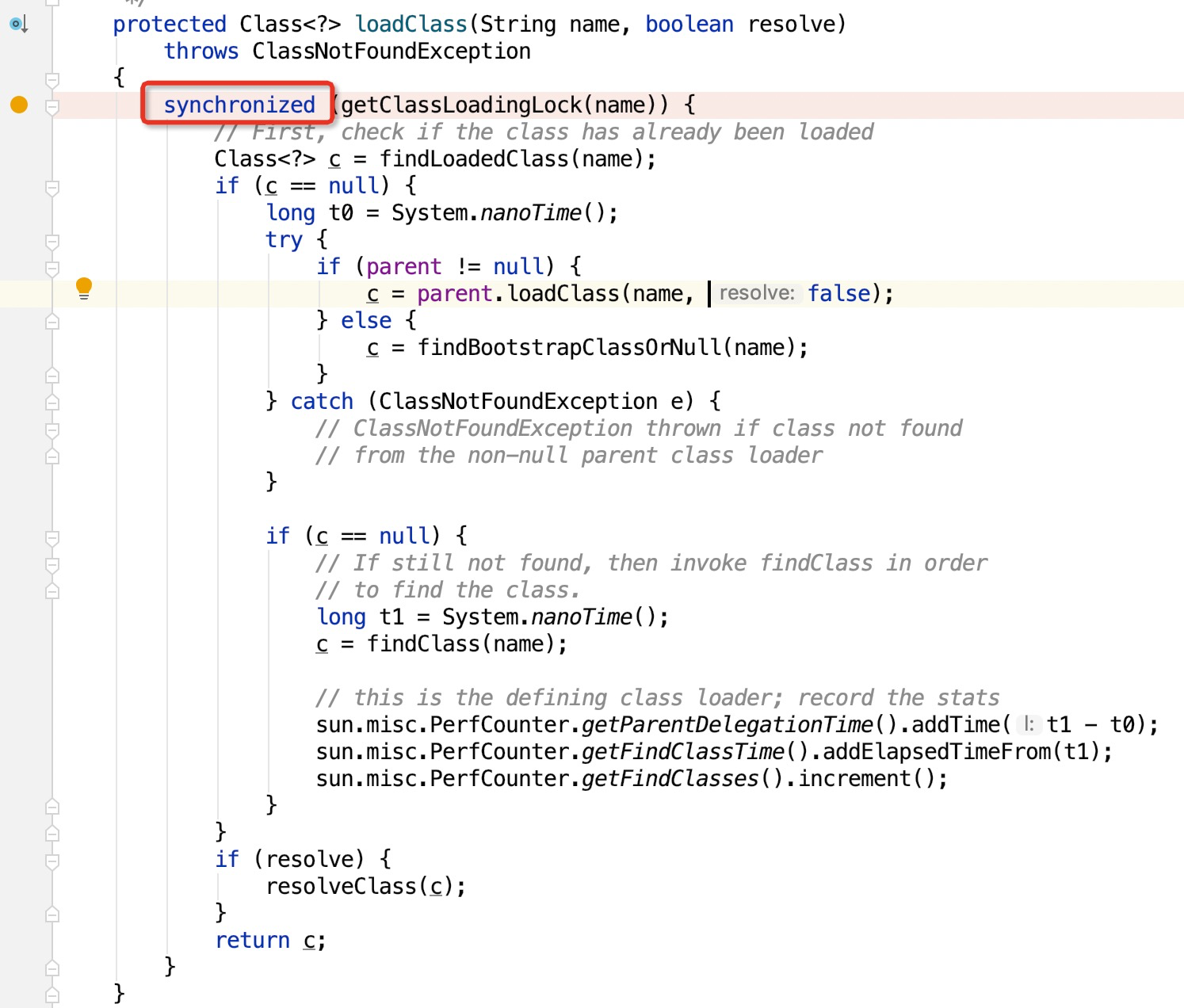
所以,当这个数据源的qps高的时候,会出现锁竞争的情况,线程dump证明了这一点: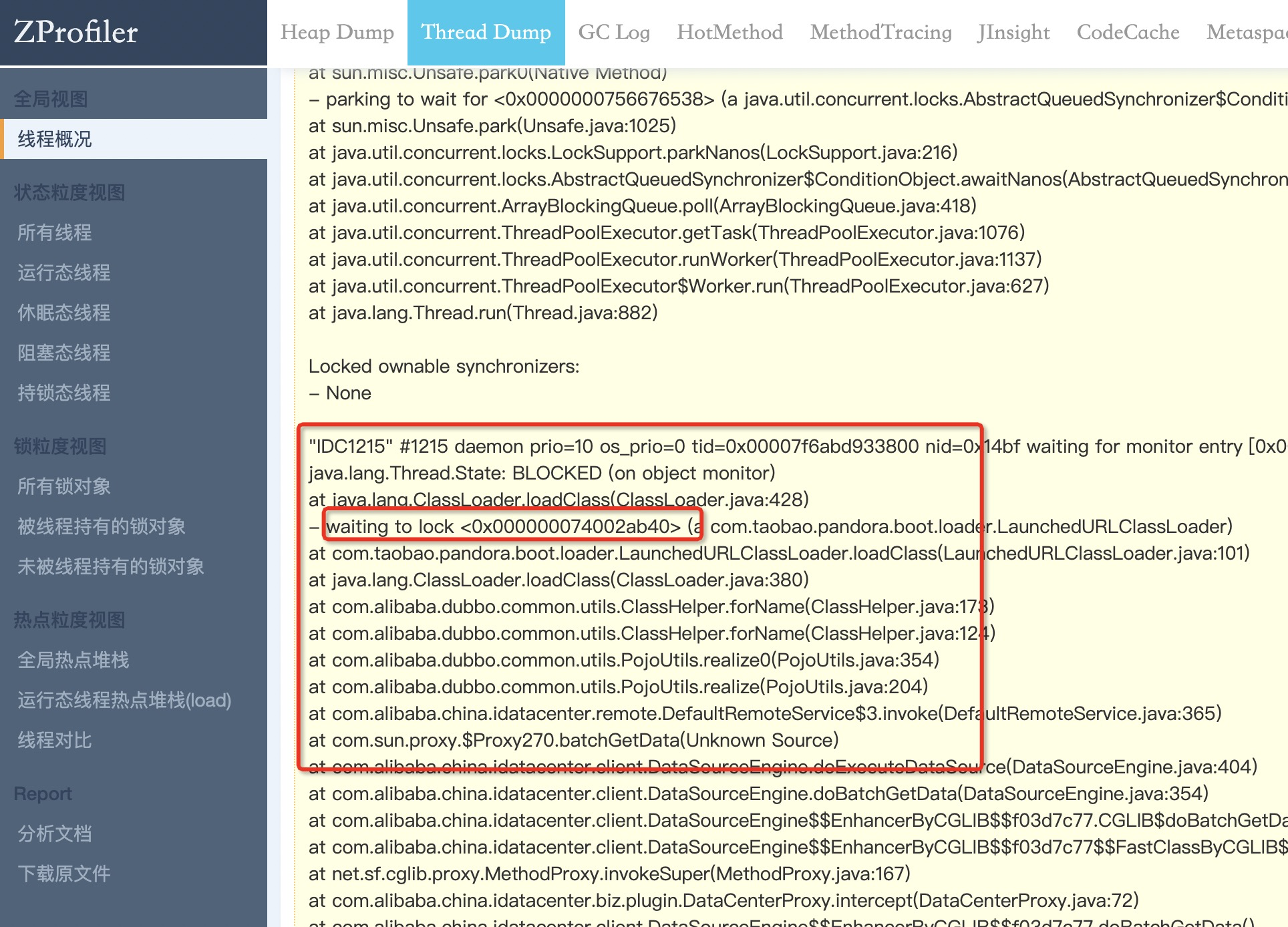
现在问题找到了,如何修复呢?正常来说,PojoUtils里面如果能将找不到的类缓存起来,那就不用每次都去执行类加载了。我去查了一下HSF官方文档,其实官方文档也提供了一个同名的PojoUtils类:com.taobao.hsf.util.PojoUtils 。这个类就实现了对无法加载的类的缓存: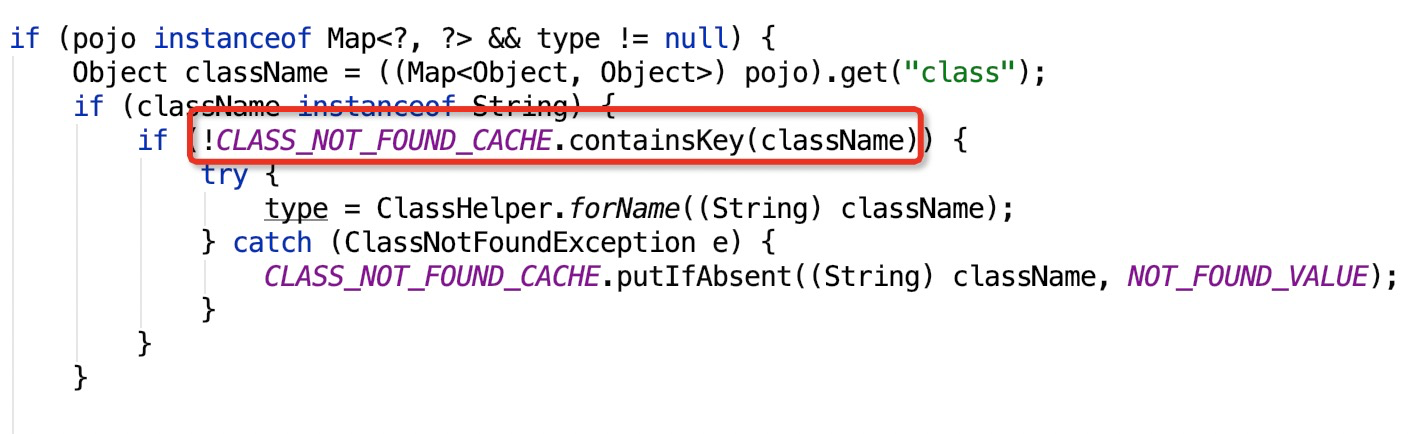
至于为什么数据中心代码里面不用HSF官方推荐的类,可能是历史原因,不去管他了。一顿疯狂操作后,其实就改了一行代码:替换com.alibaba.dubbo.common.utils.PojoUtils为com.taobao.hsf.util.PojoUtils 。
优化效果
发布代码上线后,果然有了立竿见影的效果,通过sunfire监控可以看到,数据中心机器的平均CPU利用率降低了40%左右,峰值从28.4%降到了16.7%;load降低了35%左右,峰值从3.1降低到2.0;YGC次数降低了67%左右;最终数据中心提供的hsf服务rt降低了10%,这些提升将直接加快APP中许多页面的打开速度。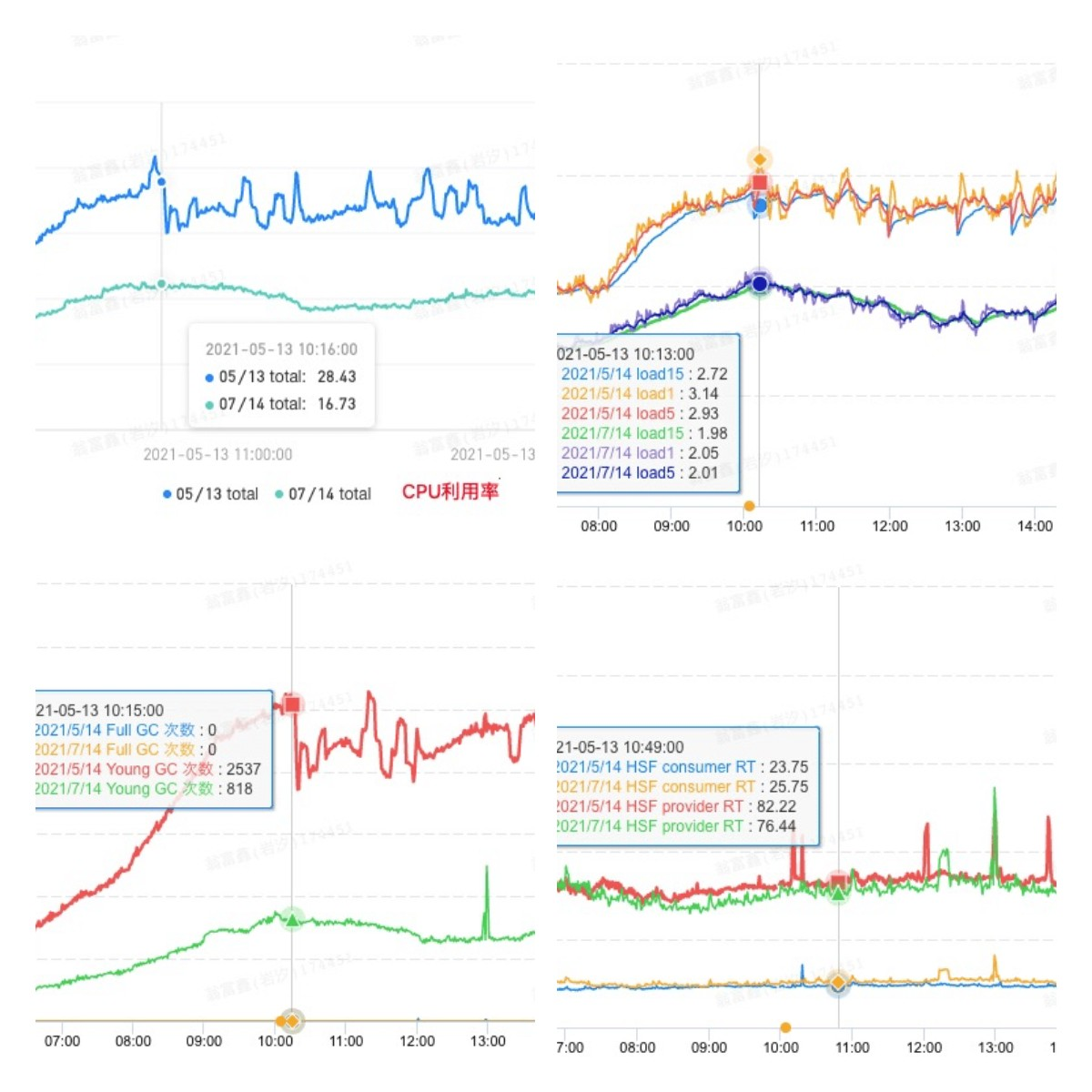
我找了很多台load偏高的机器,结果意外的发现不仅ClassLoader的问题没了,jit的问题也没了,意外之喜,原因是啥还没找到。
除了以上的几个优化尝试外,我还有一些其他比较通用的优化操作,这里我简单例举一下:
● 优化日志量,减少日志打印。这个优化在我这个应用里面十分重要,我精简了大量日志,剪裁了不必要的日志,上线后,有5%的load提升
● 日志异步打印。logback和log4j都支持异步打印日志,但都是需要手动配置的,具体配置方式就不细说了,这个优化主要是考虑到,当一个方法执行过程中如果执行了太多次同步的日志打印,对性能是有影响的(蚊子再小也是肉对吧)
总结
其实性能优化也真的是一个很大的命题,特别是当这个问题不具体的时候,因为它不像是我们平常遇到的空指针、包冲突那样有章可循,它往往没法很好的切入,甚至很多时候你可能不知道你的应用有性能问题。所以我们可以尝试利用一些工具,将一个比较泛的问题,分解成一个个具体的问题,将一个较为黑盒的操作系统问题,具象化的进入到我们熟悉的Java领域上再逐个击破,拿到好的优化效果。

