一、故障背景
在描述背景前,先补充点基础知识,以便理解下ADB PG的定位和架构:
ADB PG的定位:
这里说一下,ADB PG全称是AnalyticDB PostgreSQL,基于开源项目Greenplum构建,由阿里云深度扩展。Analytic是一个形容词,主要用于描述与分析(Analysis)相关的特性或方法。
故障背景:
1、dbstack作为阿里云数据库产品族的快速输出方案已经在多个局点部署。
2、某局点修复dbstack底座kubelet组件安全漏洞会重启kubelet,因为未知原因(日志被滚动清理了,复盘后提供了排查方向,但无法100%确定),导致部分节点上的pod被重建。
3、重建后的pod挂载了宿主机上容器自身的cgroup文件系统,未重建的pod挂载的是宿主机自身的cgroup文件系统,挂载行为发生变化。
4、重建后的pod的cgroup关于cpuset.cpus的设置值超过了20个字符,触发ADB PG的已知缺陷。
5、ADB PG集群状态异常,使用psql命令行数据库连接工具去连接数据库卡住。
6、基础知识:
a.默认情况下Pod 默认不会直接挂载宿主机上的 cgroup 文件系统,因为这样做可能会带来安全风险。如果非要挂载可以用privileged: true(很危险不推荐),或者卷挂载的方式(只需要挂载特定的目录,推荐)。
b.Kubelet 是Kubernetes集群中的一个重要组件,负责在一个节点上运行 Pod 容器。它是集群中最底层的代理,与Kubernetes API Server 通信,并确保容器按预期运行。Kubelet 负责监控和维护节点上的 Pod 状态,确保它们处于期望的状态。
二、故障排查过程
1、夜里10点,也就是修复dbstack底座变更开始后1小时。值班长接到数据库“业务读写不可用”告警,开始调度产研一起排查。
一开始并不能明确是什么原因导致的集群异常,所以登陆到Master节点,尝试使用psql连接集群,看看有哪些计算组进程down了,但是psql卡住了,无法成功登陆。
2、ps -ef | grep -i postgres这个命令就是查看PostgreSQL 相关的所有进程,发现大量backend进程处于startup状态,此现象其实属于常见现象,平时在其他故障场景下也有遇到。
如果一个backend进程长时间停留在startup状态,可能表明存在以下问题:
1
2
3
4
5认证延迟:身份验证服务或配置问题导致认证过程变慢。
资源争抢:系统资源紧张(如CPU、内存、I/O),导致进程等待资源分配。
配置错误:数据库或客户端连接参数配置不当,导致初始化过程卡住。
网络问题:网络延迟或不稳定,影响连接建立或认证信息的交换。
系统问题:Greenplum内部问题,如bug,或者系统级的锁冲突。
此时产研根据经验判断,应该是计算组进程有什么异常。
3、kill掉任意一个backend进程,让Master进入recovery模式,会释放相关的数据库连接,然后就可以使用psql连接到数据库中,查询到有大量的计算组进程down。
4、尝试用gpstop -af命令手动停止集群,但是发现已经存在新启动任务,说明管控探测Master异常,触发了重启,这里为了避免管控干扰问题修复,去杜康临时关闭HA检查。
5、等管控的启动任务结束后,进入集群,找到任意一个down的计算组进程,查看日志发现,很清楚的不停打印cgroup相关错误,此时原因基本定位到了,但是如何解决又让众人没有思路,只能各种尝试,这部分工作耗费了大量时间。
6、当时做的尝试有:
1
21)手动delete某个pod,pod重建后,cgroup错误依然存在。
2)切换到root用户下,手动写入 cpuset.cpus 相关参数值,手动重启计算组进程, cgroup 错误依然存在。
7、经过各方协调,最后在产研的建议下,修改pod的yaml里面关于cgroup的设置,修改后计算组进程立刻恢复正常,然后进行故障计算组所在pod批量修改,此步骤前后耗时不超过30min,解决问题的终极办法有时候就是很朴素,只是要找到正确的办法。命令如下:
1
2
3
4
5
6
7
8
9kubectl -n dbstack-dbaas annotate pod $podname cgroup.ark.alibabacloud.com/detail='{"engine":{"cpuset":"-1"}}' --overwrite
这里解释一下上面命令:
kubectl: 这是 Kubernetes 的命令行工具,用于与 Kubernetes API 服务器进行交互。
-n dbstack-dbaas: 这个选项指定了命名空间(namespace),这里是 dbstack-dbaas。
annotate: 这个子命令用于添加或更新 Pod 的注解。
pod $podname: 指定要操作的 Pod 名称,这里的 $podname 是一个变量,代表具体的 Pod 名称。
cgroup.ark.alibabacloud.com/detail='{"engine":{"cpuset":"-1"}}': 这是要添加或更新的注解及其值。注解名称是 cgroup.ark.alibabacloud.com/detail,值是一个 JSON 字符串 { "engine": { "cpuset": "-1" } }。
--overwrite: 这个标志表示如果注解已经存在,则覆盖原有的值。
命令输入后,返回pod/my-pod annotated这表明注解已被成功添加或更新。当然,在修改前,同时对dbaas库里面的cgroup相关配置做了备份,防止需要回滚。
8、至此,时间已经是凌晨2点。集群恢复可用状态,虽然有部分计算组进程down,集群性能下降,但是可以开始承接业务读写。不过问题到此,远远没有结束,更刺激的还在后面。
9、时间来到故障发生后凌晨4点,现场反馈大量跑批任务报错,相关人员立即介入排查。问题报错是相关任务要读取某些表,提示底层文件不存在!发现是因为故障的时候,计算组主备切换,其实备节点顶替主节点行使主节点的职责的时候,当时备节点和主节点并不完全同步,存在部分内容主节点有,但是备节点没有的情况。
10、尝试将报错中提示的表不存在的文件从计算组的主节点拷贝到备节点的数据目录,手动跑了相关的任务,提示运行成功。
11、但是报错的任务太多,涉及到的表也太多,一个个手动拷贝报错的文件显然是不可取的,所以决定手动进行故障的计算组主备重新切换,让原先的主节点重新顶替备节点进行工作。切换后任务继续运行,直至早上9点,全部任务结束,赶在客户使用数据前输出,紧张的应急只是告一段落,问题还没有完全结束。
12、时间来到故障发生后第二日10点,现场反馈,业务人员读取外部表报错,开发和DBA继续介入排查。
13、现场使用的是pxf访问hadoop外表,报错提示和pxf认证相关,krb5问题,问题很明确,重新初始化pxf的krb5相关配置即可,但是如何重新初始化呢?经过现场排查,的确凡是被新建的计算组pod里面关于krb5的认证相关配置文件均不存在,未重建的计算组pod里面是有相关配置文件的。
14、此时要么手动拷贝相关配置文件,要么批量重新生成配置文件,很显然手动拷贝工作量大,还有可能遗漏,也很耗费时间。随后决定走批量重新生成的办法,正好现场之前处理过类似问题,在产研的建议下排查到pxf初始化任务被实例的主备切换任务阻塞,把杜康上相关中断的任务处理掉以后,pxf开始自动初始化,初始化正常后业务读写正常。
15、时间来到故障发生后第二日11点,现场反馈,业务人员表示数据库查询缓慢。其实这个问题很明确,集群有部分计算组down,在修复中,在没有完全修复完毕,集群处于平衡状态下,集群性能会有很大折扣,同时叠加夜间进行了大量跑批,修复速度会进一步被拖慢。
16、同时产研提醒,因为down的计算组进程过多,需要注意并行修复,避免串行修复,时间进一步拉长。给现场重新分发了新的修复脚本后,按照预期进行修复,但是因为要修复的太多,同时有业务读写,修复进度一直不太理想。
17、时间来到故障发生后第二日23点,现场各方沟通后,决定停止业务读写,全力保障修复进度。
18、时间来到故障发生后第三日7点,集群修复结束,重新回归平衡,问题算是彻底修复完成。随后针对此次应急,内部进行了深入复盘。
三、故障解析 & 事后思考
1、此故障属于ADB PG-6.3.10.14之前版本的缺陷,我们后来也在dbstack环境实例化一个和现场同版本的实例。此处得到了产研同学的大力支持,通过手动准备相关版本镜像、修改dbaas相关表的办法,成功实例化了和现场同样版本的实例。
2、因为现场是大量计算组进程的pod被重建,所以事后我们认为cgroup初始化出错问题只会出现在计算组相关进程,其实不是的,Master节点也会出现。
正好新实例化的实例Master节点的cpu核心是8核心,也使用了超过20字符的方式设置cgroup,在按照演练方案,执行ADB PG开启cgroup功能后,问题直接复现,还没到如何解决计算组进程cgroup初始化异常那一步,比现场遇到的场景更加复杂,也是比较出乎意料。
开启cgroup就是修改ADB PG的参数gp_resource_manager从queue改为group,修改完重启生效。如图: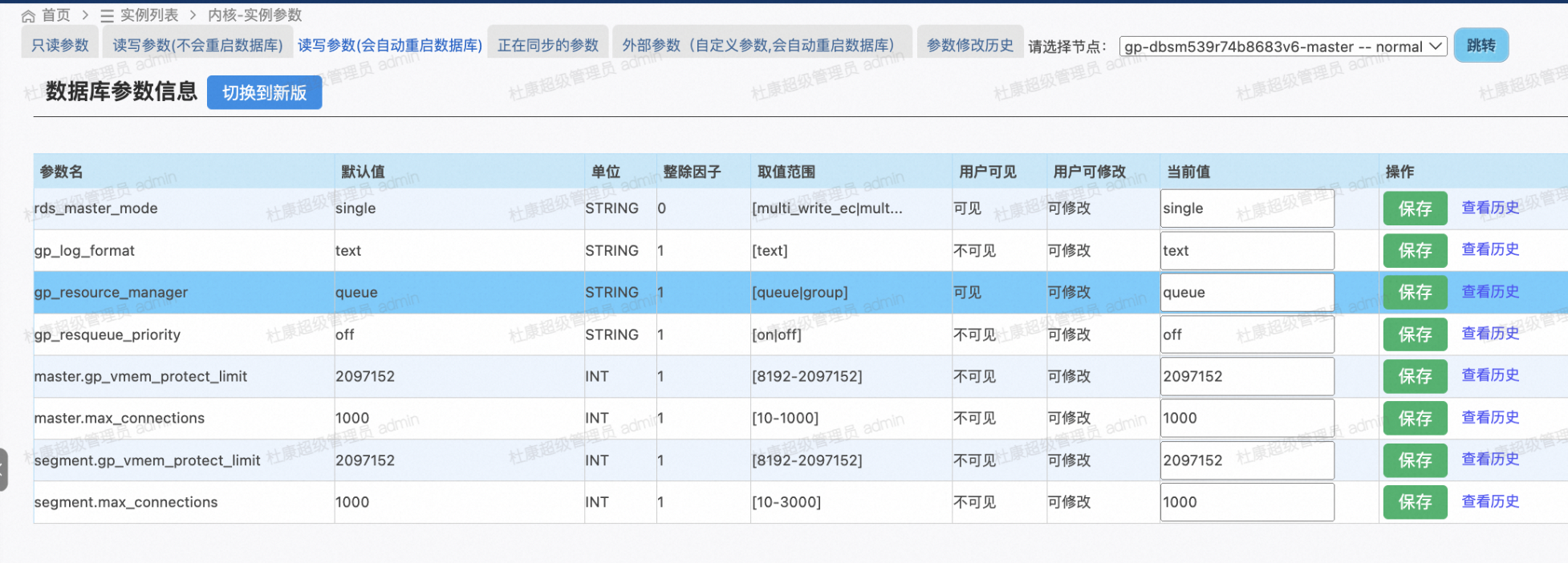
出现故障的实例的Master的cgroup设置: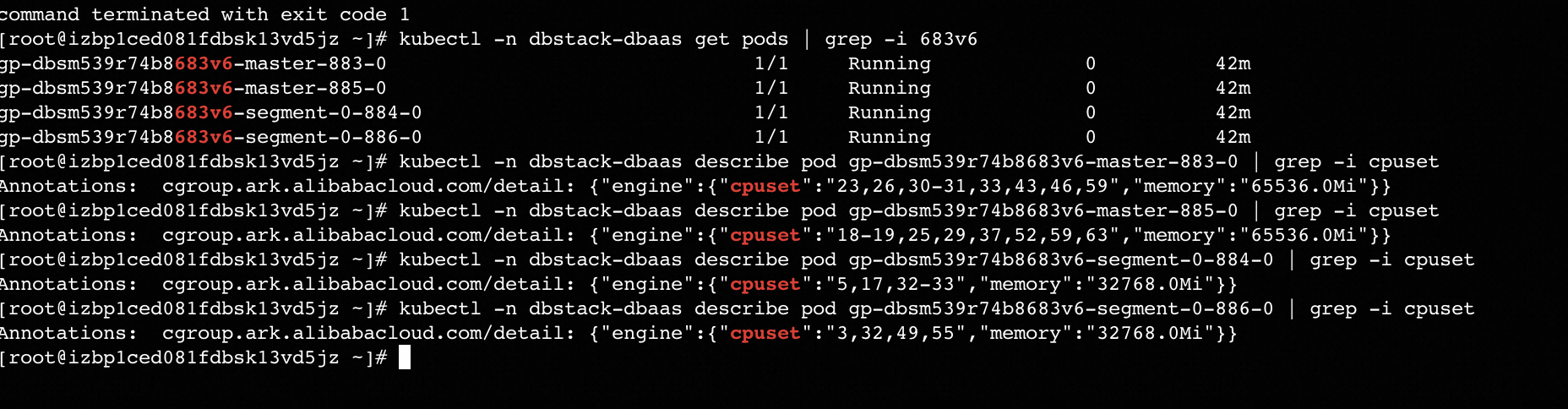
3、cpuset.cpus的设置值超过20个字符触发缺陷的详细描述如下:
假如服务器有64核心(编号从0-64),计算组分配了32核心,cpuset.cpus里面的值就是这样:0,1,2-3,4-6,11-13,15-18,...。这些字符串表示绑定到32个cpu核心,但是字符(逗号、横线)加起来超过了20个字符,导致容器启动后,cgroup关于cpuset.cpus的设置失败,如下图: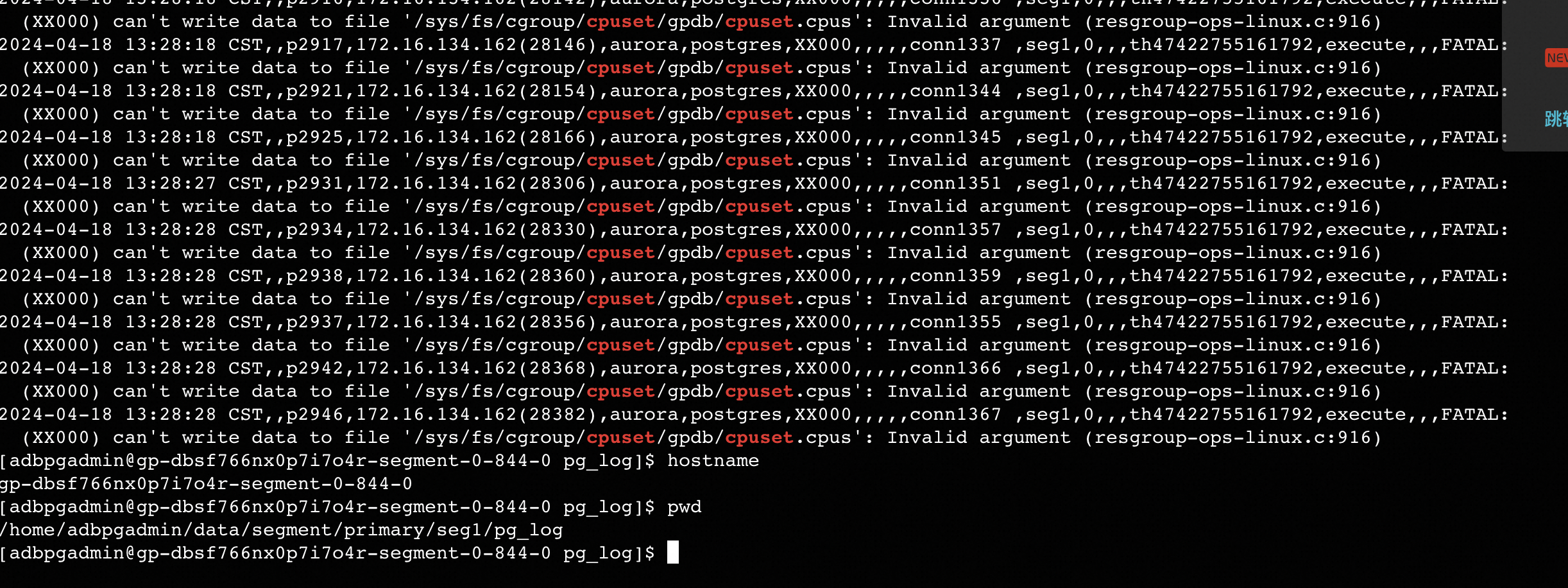
4、出现这种问题的临时解法如下:
1
2
31)先订正slave的cgroup,缩小到20字符以内,命令:kubectl -n dbstack-dbaas annotate pod $podname cgroup.ark.alibabacloud.com/detail='{"engine":{"cpuset":"-1"}}' --overwrite
2)再订正master的cgroup,缩小到20字符以内,命令参考第一步命令即可
3)剩余计算组进程所在pod,如果有cgroup设置超过20个字符的,依次订正cgroup到20字符以内
永久性解法还是推进项目进行内核升级。
5、为什么使用psql工具去连接数据库会卡住?因为有大量的ADB PG的计算组进程处于非正常状态,ADB PG的Master去探测计算组进程是否正常无法得到响应,Master不停的探测,就会不断消耗数据库可用连接直至耗尽。最后给运维人员的直观感受就是使用psql工具以管理员用户去连接数据库会卡住,同时提示数据库连接数不足。
6、 集群异常后修复效率问题:如果发现集群有大面积计算组进程down,需要和业务方第一时间进行沟通,争取能及时停止业务读写,全力保障修复工作高优先级顺利进行,边修复边使用,不光修复的慢,使用方体验也不佳。
7、升级过程中常见的组件间配合问题:底层组件升级,忽略了上层应用的拓扑,有可能会触发ADB PG同一个主备组的进程同一时刻被重建,导致集群不可用。
之前也遇到过类似故障,升级过程中调用方未检查被调用方状态,未检查调用执行是否成功,最终双方均未及时抛错,显示升级过程一切正常,直至业务真实调用的时候,才发现其实有故障隐患。
目前我司的产品组件众多,调用关系复杂,尤其是在升级这种大变更场景下,相对完善的检查机制和及时抛错机制可以及时发现升级的异常,将故障前移。这块儿只能依靠告警来发现问题,然后上有经验的人来及时剖析问题,不断完善产品。或者现场升级后及时关注业务指标变化,在故障发生后,及时介入处理,将影响降到最低。

