背景交代
在公司的开发环境搞到一个tesla T4 16显存的GPU服务器(同时还有16core 64G),搭配我之前的 32core 128G的CPU服务器,这俩可以做一个集群了,我给他俩的分工就是:CPU当k8s-master,GPU当k8s-worker。
这么考虑的原因是:
- CPU服务器有32core,毕竟在master上是要运营“api server、scheduler、etcd、controller”这么多组件,所以需要一个逻辑密集型的服务器,而这些工作可以完全不需要GPU。而且我这个服务器的内存128G,能装很多东西~
- GPU唯一的使命就是把显存贡献给大模型,如果master节点的管理任务在GPU节点上,那么消耗GPU的CPU资源是不值当的。
他俩的配合流程是:
- 这个GPU上主要跑的就是docker和k3s-agent,在CPU master上执行
kubectl apply xxx,master看到yaml里的nodeSeletor写的是gpu的服务器,就把任务下发。 - GPU服务器的k3s-agent监听6443端口知道属于自己的任务来了。
- GPU让docker去按照yaml里的要求拉取镜像。
- 启动任务POD,反向给master同步。
搭建GPU的环境
首先,先确认GPU和CPU的服务器是互通的,互相的ping 和curl都是没问题的。
去下载一个docker,注意调整docker的/etc/docker/daemon.json:
1 | root@gpu-worker-01:/data00/home/chenshuo.007# cat /etc/docker/daemon.json |
然后启动docker 看一下挂载的目录是否正确:
1 | systemctl daemon-reload |
执行 nvidia-smi 看一下显卡是否启动了:
然后去cpu master机器上看一下 node-token,默认是在/var/lib/rancher/k3s/server/node-token里,把这个token复制出来,在GPU的服务器里:
1 | curl -Lo k3s_install.sh https://rancher-mirror.oss-cn-beijing.aliyuncs.com/k3s/k3s-install.sh |
在gpu的服务器使用sudo journalctl -u k3s-agent -f ,时刻关注日志的情况,如果日志没问题的话,就能在cpu master服务器上,看到2个node ready:
在master上给这个GPU 服务器加一个label:kubectl label node gpu-worker-01 accelerator=nvidia-t4。
然后我们要在gpu服务器上启动一个daemonset,内容如下:
1 | kubectl apply -f - <<EOF |
然后我这里发现一个问题,用kubectl get pods -A来看,看到nvidia-device-plugin-XXX是在不断的重启:


这里我们一个一个的看event:
- Successfully assigned:调度器(Scheduler)成功地为这个 Pod 在集群中找到了一个合适的家(Node)。
- Container image … already present:运行这个 Pod 所需的容器镜像(
nvcr.io/nvidia/k8s-device-plugin:v0.18.1)已经在本地存在了,不需要重新下载。 - Created container:
kubelet成功地根据镜像创建了容器实例。 - Started container:
kubelet成功地执行了启动容器的命令。 - Last State: Terminated, Reason: Error, Exit Code: 1:容器在启动后,因为内部程序错误,立刻就退出了,并且返回了一个非零的退出码(
1表示有错误)。 - 然后继续重启
遇到这种问题我觉得可以去看看具体的日志了,kubectl logs nvidia-device-plugin-daemonset-r8ht9 -n kube-system --previous , 发现里面报错: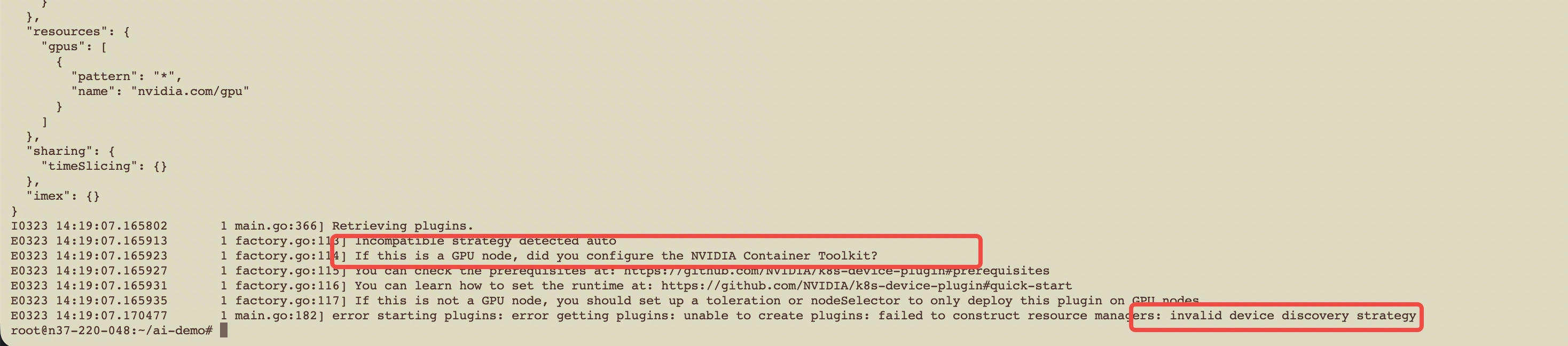
重点看第三句,If this is a GPU node, did you configure the NVIDIA Container Toolkit? 翻译过来就是“如果这是个GPU节点,你配置好NVIDIA容器工具包(NVIDIA Container Toolkit)了吗?”,这就是问题,我的GPU没有NVIDIA Container Toolkit,于是就退出了。
安装方法如下:
1 | # 在 gpu-worker-01 节点上执行 |
至此,准备工作终于完成了:
- gpu服务器已经顺利加入集群,并且身份是worker.
- gpu服务器配置好了label。
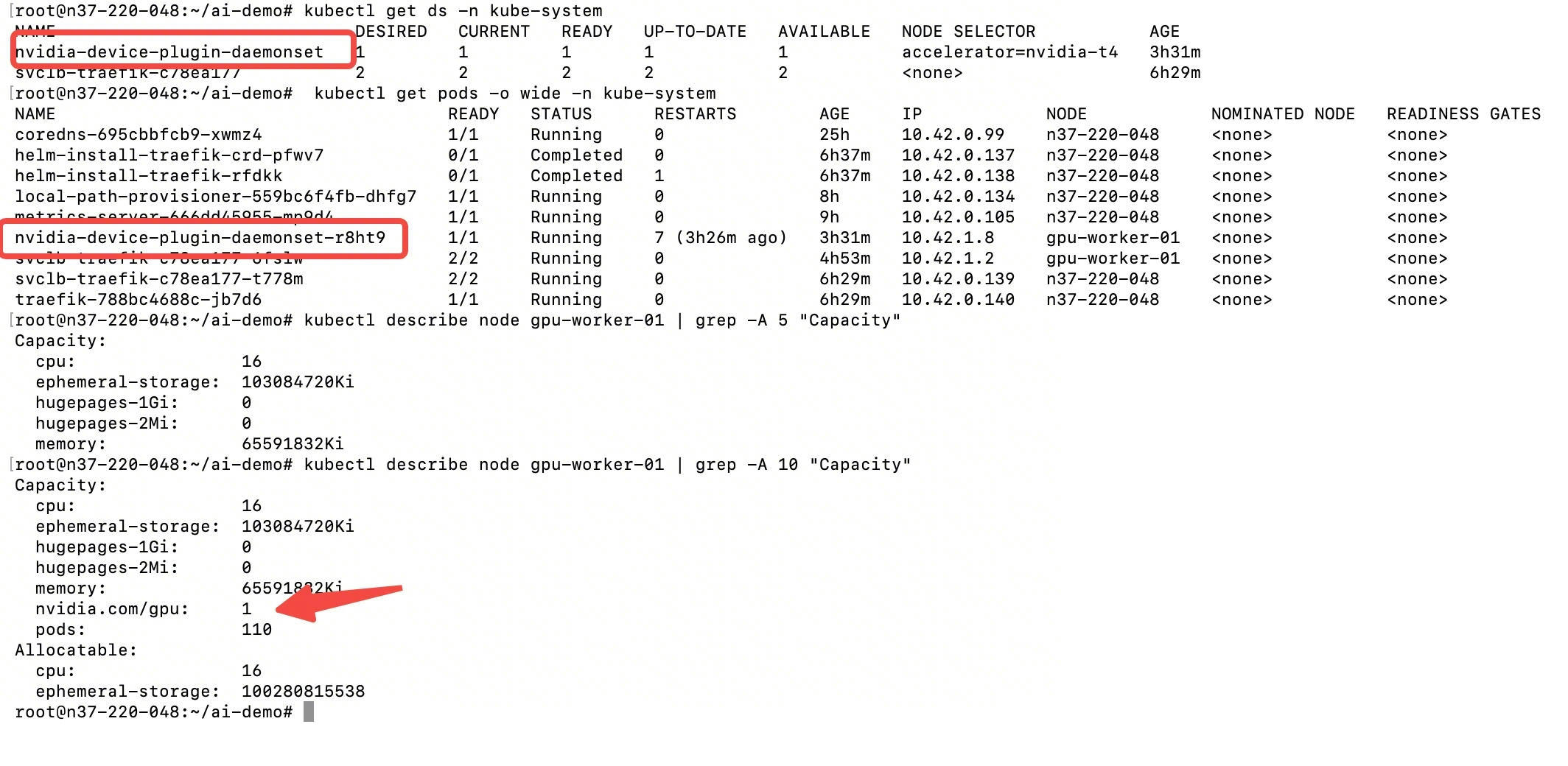
- GPU服务器安装好了
NVIDIA Container Toolkit,nvidia-device-plugin-XXX RS已经能OK了。 - GPU服务器启动一个nvidia-device-plugin的ds,然后他会起一个pod,这个pod的存在就是让master知道这个节点是有一个t4 显卡。
测试一下GPU的威力
现在GPU服务器已经就位,那么我们就可以搞一个可以识别图片的ai了,毕竟我们之前那个CPU的大模型只能识别文字,工作中我们还是要扔一些图片进去的。
首先我们启动一个ollama的pod,让它准确的去调度gpu的服务器:
1 | apiVersion: apps/v1 |
启动了之后,就看到有个ollama的pod已经在GPU worker上生成了。但是没有具体的大模型,所以我们选择用Qwen3.5,目前它能力是很强的。
1 | ollama pull qwen3.5:latest # 然后等待下载完毕 |

但是这里要确认一下ollama ps,看一下究竟是cpu在运行还是gpu在运行。比如我这里就发现“我的GPU在摸鱼,CPU在干活”:

于是可以先kubectl logs <GPU pod> | grep -i 'CUDA' :
这里为空,说明这个GPU POD 启动的时候,没有发现GPU编号,于是在“应该卷GPU的场景里卷CPU”。
我后来查了一下,是因为我tesla T4跑的是450版本的驱动,最高只支持CUDA 10,而qwen 3.5是比较新的,要CUDA 12以上的版本,于是就在GPU上更新一下驱动:
1 | apt-cache search nvidia-driver |
重启之后,检查一下k3s-agent和docker的状态,再来刷新一下nvidia-smi:
此时再跑一个大模型的识图任务,就看到效果了,GPU开始工作了,而且返回字的速度也明显加快了:

这样才是真正的实现了“GPU通过ai大模型分析图形“的效果:
最后要注意一下,我这里做了图片上传覆盖的逻辑,也就是说如果上传了一个1.jpg,再上传另一幅图片但是也叫1.jpg的话,后者会覆盖前者。这样的好处一个是好管理,节省磁盘空间。
缺点就是:
- 缓存幻觉:如果两个用户(或你先后两次)上传了同名但内容不同的图片,后上传的会把前面的冲掉。
- 并发冲突:如果 AI 正在读第一个 yaoming.jpg 进行推理,此时第二个同名文件写进来,可能会导致 AI 读取文件流中断或报错。
- 历史追溯难:数据库 history 表里记录的图片路径都是同一个,你以后想看“昨天那个姚明”和“今天这个姚明”的区别,就找不到了。
- 最重要的一点,如果直接用了
os.path.join(文件路径),那么遇到用户上传的文件故意起名叫”../../etc/hosts”,这样很有可能真保存到/etc/hosts里,他猜这个上传的路径就是根路径的第二级,第二级不对就第三极。反正就是破坏你的原文件。
所以建议给文件名加个“时间戳”或者“随机指纹” + secure_filename,secure_filename可以过滤掉危险字符(比如/ 和 .. 这样的路径字段),这样唯一性+安全就都解决了。

