以前部署的流程是这样的:开发给运维一个jenkins地址,运维在桌面打开jenkins页面下载zip包,然后Xftp传递到nfs共享挂载盘里。不过我们现在开发都把模块的名字取得特别长而且易混(天才一般的取名方式),最重要的是遇到大型上线,jenkins里会有N多个zip包,如图: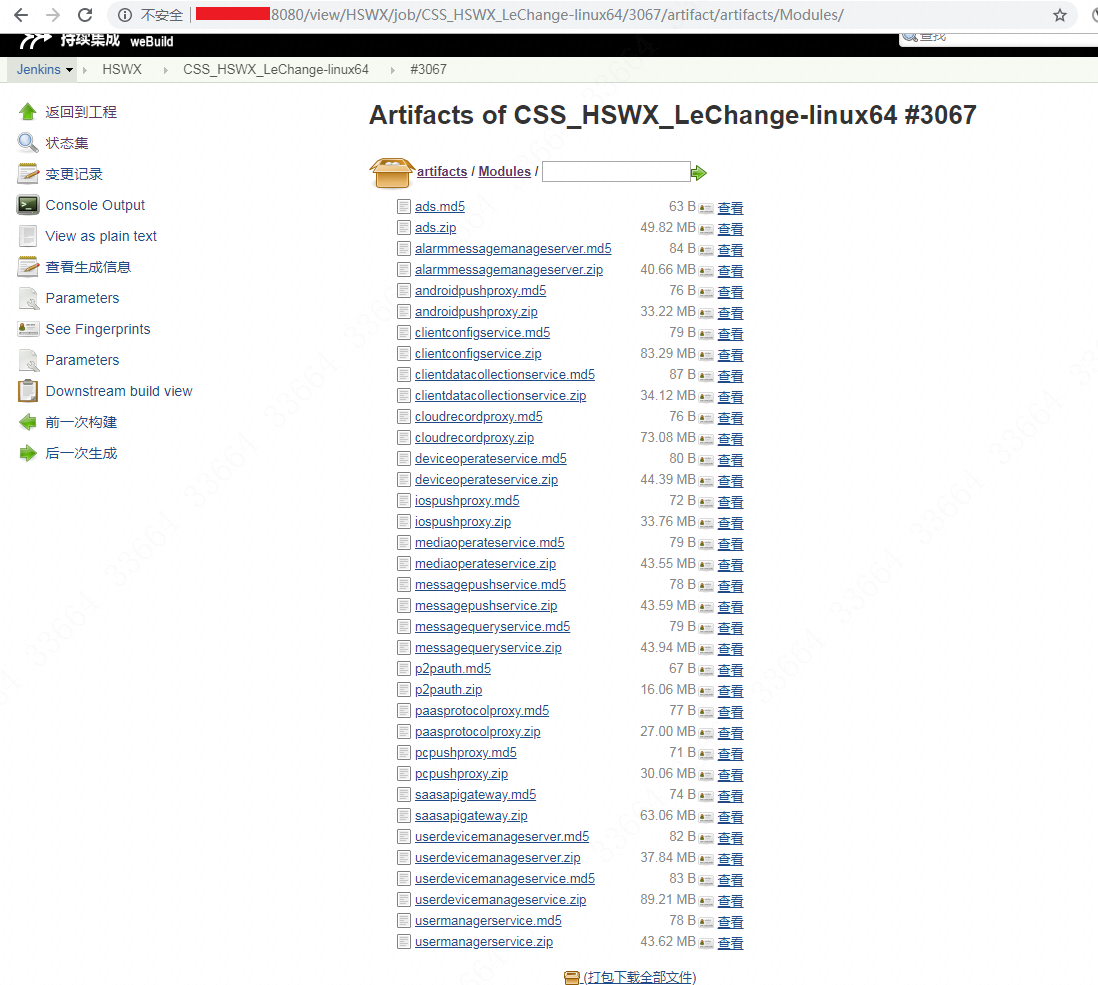
这样一个一个点下来,连点十多下然后再上传的行为不仅蠢还很容易遗漏,于是就写一个脚本来解决这个问题,实现“一键传包”。脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112# !/usr/bin/env python
# -*- coding:utf-8 -*-
# 作者:ChrisChan
# 用途:爬取jenkins网页的所有的zip连接,下载完毕之后上传到文件服务器里,脚本需要安装paramiko,tqdm和BeautifulSoup
import os
import re
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
import paramiko
import datetime
zip_url = []
zip_name = []
folder_path = r'F:/Jenkins/'
if os.path.exists(folder_path) == False: # 判断文件夹是否已经存在
os.makedirs(folder_path) # 创建文件夹
print("jenkins文件夹已经创建完毕!")
BASE_URL = input("请输入jenkins网址:") # 由于input输入http地址自带超链接,回车就直接弹开网页,所以url末尾是以 空格 结束
if BASE_URL.endswith('/ '):
url = str.rstrip(BASE_URL) + "artifact/artifacts/Modules/" # 去掉末尾空格
else:
url = str.rstrip(BASE_URL) + "/artifact/artifacts/Modules/" # 补全
print("准备去",url,"里下载所有的zip文件")
# 爬取页面所有的zip地址
page = requests.get(url).text
pagesoup = BeautifulSoup(page,'lxml')
for link in pagesoup.find_all(name='a',attrs={"href":re.compile(r'.zip$')}): # 获取所有zip结尾的,如果是开头就是^
zipname = link.get('href')
zip_url.append(url + zipname)
zip_name.append(zipname)
#print(zip_url) # 得到完整的zip包下载链接
zip_dict = dict(zip(zip_name, zip_url)) #把下载包名和链接做成字典
if ("./*zip*/Modules.zip") in zip_dict.keys(): # 判断字典里是否存在这个元素
zip_dict.pop("./*zip*/Modules.zip")
print("该页面有 %s 个zip文件:" % len(zip_dict))
else:
print("该页面有 %s 个zip文件:" % len(zip_dict))
# 下载文件
def downloadFile(name,file_url):
resp = requests.get(url=file_url, stream=True)
content_size = int(resp.headers['Content-Length']) / 1024
with open(folder_path+name, "wb") as f:
print("安装包整个大小是:", content_size, 'k,开始下载...')
for data in tqdm(iterable=resp.iter_content(1024), total=content_size, unit='k', desc=name): #使用tqdm做了一个进度条
try:
f.write(data)
except Exception as e:
print(repr(e))
print('\r\n' + name + "已经下载完毕!")
# 上传到share盘
def uploadFile(_localDir, _remoteDir):
_localDir = folder_path
_remoteDir = remote_path
try:
t = paramiko.Transport((hostIP, port)) # 这里一定是双括号!
t.connect(username=username, password=password)
sftp = paramiko.SFTPClient.from_transport(t)
print('现在开始上传文件到/share/bag %s ' % datetime.datetime.now())
for root, dirs, files in os.walk(_localDir):
# 相对与_localDir的路径
remoteRoot = root.replace("\\", "/")
# 文件名,不包括路径
for filespath in files:
local_file = os.path.join(root, filespath)
remote_file = remote_path + "/" + filespath
remote_file = remote_file.replace("//", "/")
try:
sftp.put(local_file, remote_file)
except Exception as e:
sftp.mkdir(os.path.split(remote_file)[0])
sftp.put(local_file, remote_file)
print("%s 上传成功!远程地址是 %s " % (local_file, remote_file))
for name in dirs:
remoteDir = _remoteDir + "/" + remoteRoot + "/" + name
remoteDir = remoteDir.replace("//", "/")
print("remoteDir ", remoteDir)
try:
sftp.mkdir(remoteDir)
print("mkdir path %s" % remoteDir)
except Exception as e:
pass
print('文件已经全部上传完毕! %s ' % datetime.datetime.now())
t.close()
except Exception as e:
print(e)
if __name__ == '__main__':
for item in zip_dict:
if item:
downloadFile(item, zip_dict[item])
else:
print("文件不存在,无法下载!")
hostIP = "文件服务器的外网IP"
port = 目标端口
username = "连接账号"
password = "连接密码"
remote_path = "远程路径" # 这里注意文件夹权限
uploadFile(folder_path, remote_path)
执行效果如下:
脚本可以改进的几个地方:
- 使用多进程,提高下载和上传效率;
- 不使用服务器,而是本地将文件上传到云存储,然后在部署的时候,模块服务器通过内网下载对应的zip包或者在dockerfile里就可以直接
ADD 云存储路径; - 服务器或者是oss信息,单独保存在配置文件里,然后使用
configparser方法读取出来;

