添加告警配置
在https://rorschachchan.github.io/2019/10/08/%E4%BD%BF%E7%94%A8Docker%E9%83%A8%E7%BD%B2Prometheus/ 里已经搭建好了Prometheus,当时是把主配置文件prometheus.yml写在了/mnt/promethues/server,然后挂载到相关容器里。现在也在相同目录里编写一个rules.yml,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: load15在告警! # 告警规则的名称
expr: node_load15{group="server",instance="172.31.0.85:9100",job="server"} > 0 #给予PromQL的表达式的告警触发条件
for: 1m #触发条件持续多久之后发送告警
labels:
severity: node_load #自定义标签
annotations: #描述,这段信息会作为参数发送给Alertmanager
summary: "实例 {{ $labels.instance }} 的load15大于 0"
description: "{{ $labels.instance }} of job {{ $labels.job }} 值大于 0."
# Alert for any instance that has a median request latency >1s.
- alert: gothreads过多啊!
expr: go_threads{group="server",instance="172.31.0.85:9100",job="server"} > 5
for: 1m
annotations:
summary: "{{ $labels.instance }}的gothreads过多"
description: "{{ $labels.instance }} has a high gotheads: (current value: {{ $value }}s)."
保存退出之后,在prometheus.yml里的rule_files字段做一下修改:
1
2rule_files:
- 'rules.yml' #将刚刚编写的rules.yml结合进去
然后重启一下prometheus(如果不是容器部署的,就是killall -HUP prometheus),再去Prometheus的web界面,先是Status--Rules,看到我们的规则已经导入进去了,并且正常在运行: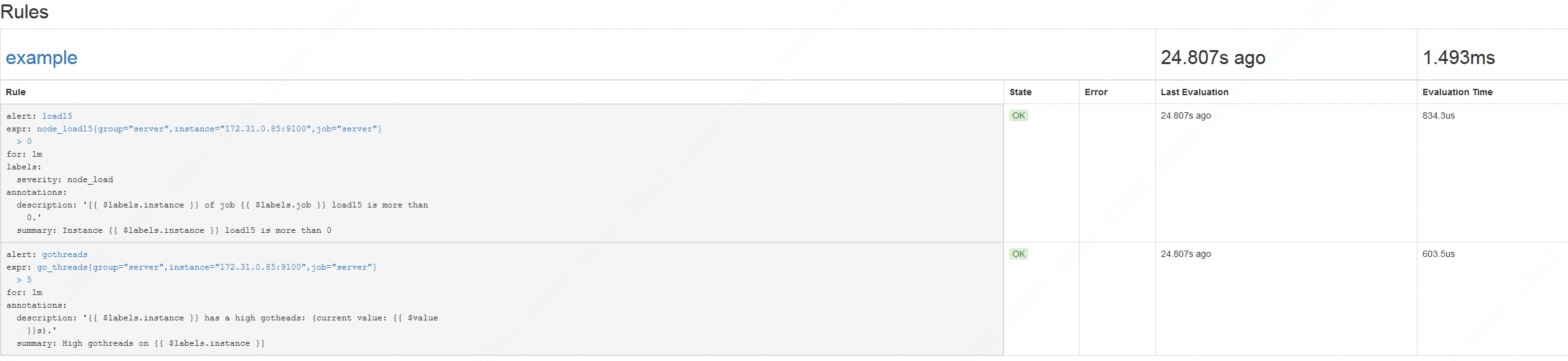
再点击Alerts,就会看到目前告警处于pending,也就是说准备要告警了: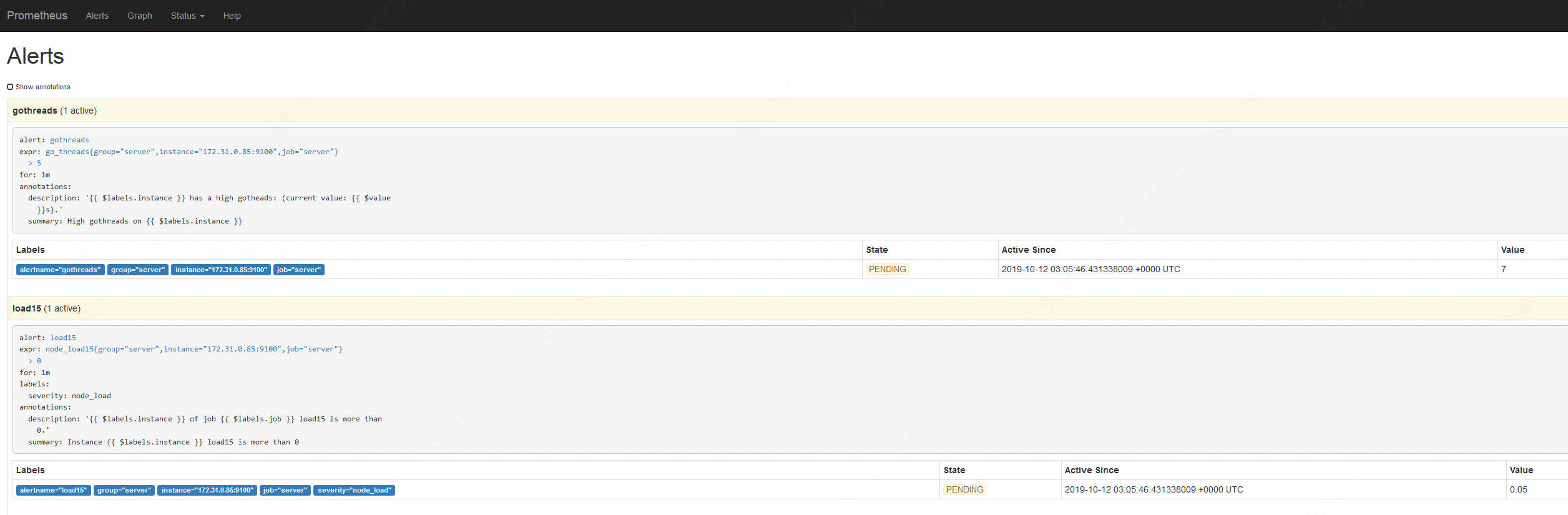
刷新一下,就看到状态已经变成了Firing,即告警了: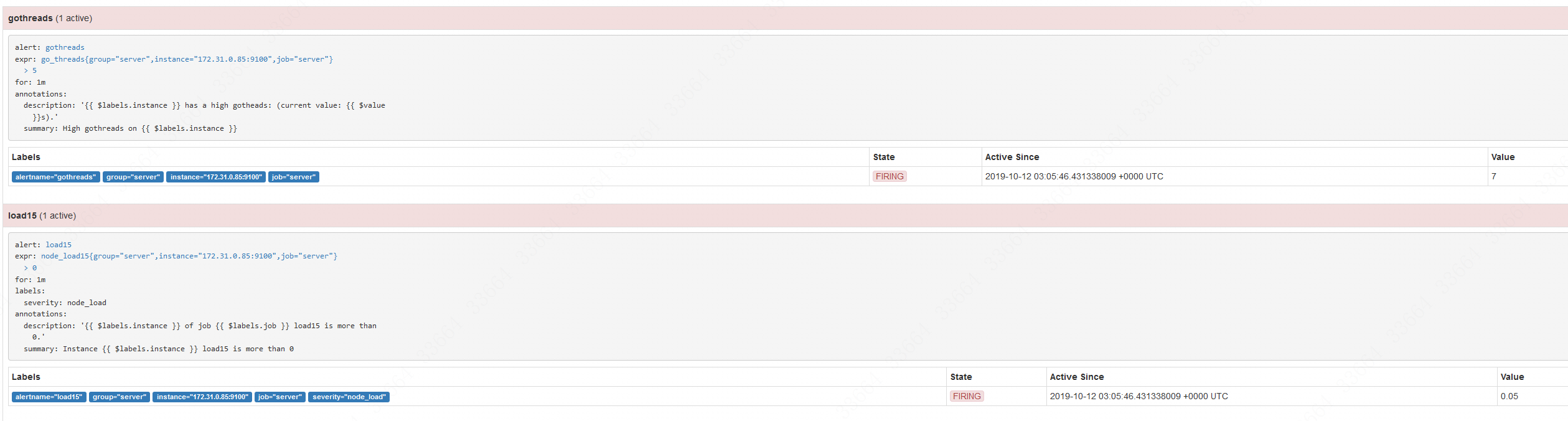
配置已经成功!不过不要过分激动,这个demo实在是太简单了,我们会在实际的工作里根据具体的场景增加一下难度。
安装Alertmanager
目前我们已经配置了告警但是还没有配置发送通知,而实现发送通知就需要靠Alertmanager来完成。正常来说Alertmanager没必要跟Prometheus装在一起,只要他俩能正常通讯即可。但是我资源紧张,就安装到一台服务器里了,具体安装方法如下:
1
2
3
4
5cd /mnt/ #我安装在mnt目录下
wget https://github.com/prometheus/alertmanager/releases/download/v0.19.0/alertmanager-0.19.0.linux-amd64.tar.gz
tar -zxvf alertmanager-0.19.0.linux-amd64.tar.gz
cd alertmanager-0.19.0.linux-amd64
./alertmanager #这个是前台运行的
启动之后,发现9093和9094这两个端口开启了。此时我们再回到prometheus.yml,在最后添加如下内容,把Alertmanager配置到prometheus.yml中:
1
2
3
4
5
6alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "172.31.0.85:9093" #这个是Alertmanager所在的服务器IP地址
这个配置告诉Prometheus,当发生告警时,将告警信息发送到Alertmanager,Alertmanager的地址为http://172.31.0.85:9093。也可以使用命名行的方式指定Alertmanager:
1
./prometheus -alertmanager.url=http://172.31.0.85:9093
此时我们登陆http://Alertmanager公网IP:9093/#/alerts,就会看到prometheus的alerts的内容出现在了Alertmanager里:
然后点击具体的告警项目,就会看到一些细节,比如我们在rules.yml里写的description和summary: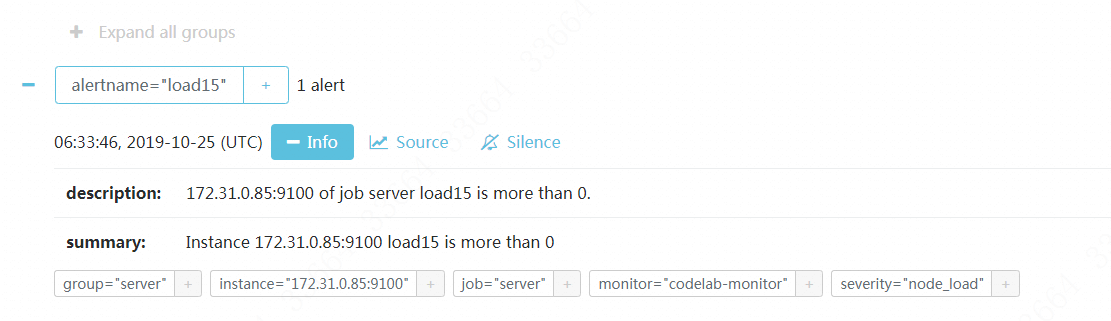
配置Alertmanager实现邮箱告警
编辑alertmanager.yml如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'chenx1242@163.com'
smtp_auth_username: 'chenx1242@163.com'
smtp_auth_password: '这里邮箱的密码'
smtp_require_tls: false #注意这个一定要写false,默认是true,若不改成false会有require_tls' is true (default) but \"smtp.qq.com:465\" does not advertise the STARTTLS extension
#templates:
# - './template/*.tmpl'
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
group_by: ['chentest'] # 这里的标签列表是接收到报警信息后的重新分组标签
group_wait: 10s # 第一次等待多久时间发送一组警报的通知
group_interval: 10s # 在发送新警报前的等待时间
repeat_interval: 1m # 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
receiver: 'GOOGLE-email' # 发送警报的接收者的名称,与receivers name的名称相同
receivers:
- name: 'GOOGLE-email'
email_configs: # 邮箱配置
- send_resolved: true # 告警解决是否通知,默认是不通知
to: 'chenshuo955@gmail.com'
#html: '{{ template "email.html" . }}'
#headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
Alertmanager检查配置文件的语句:./amtool check-config alertmanager.yml。如果出现SUCCESS即文件OK!
默认Alertmanager的启动方式:./alertmanager --config.file=alertmanager.yml,不指定config.file则会去读取alertmanager.yml,不过我们还是用systemctl来启动,先编写
1
2
3
4
5
6
7
8[Unit]
Description=alertmanager
[Service]
Restart=on-failure
ExecStart=/mnt/alertmanager-0.19.0.linux-amd64/alertmanager --config.file=/mnt/alertmanager-0.19.0.linux-amd64/alertmanager.yml
[Install]
WantedBy=multi-user.target
保存之后通过systemctl start alertmanager启动。既然是systemctl启动的进程,那么查看日志的方法就是sudo journalctl _PID=alertmanager进程号:
稍等一会,Gmail就会受到邮件,如图: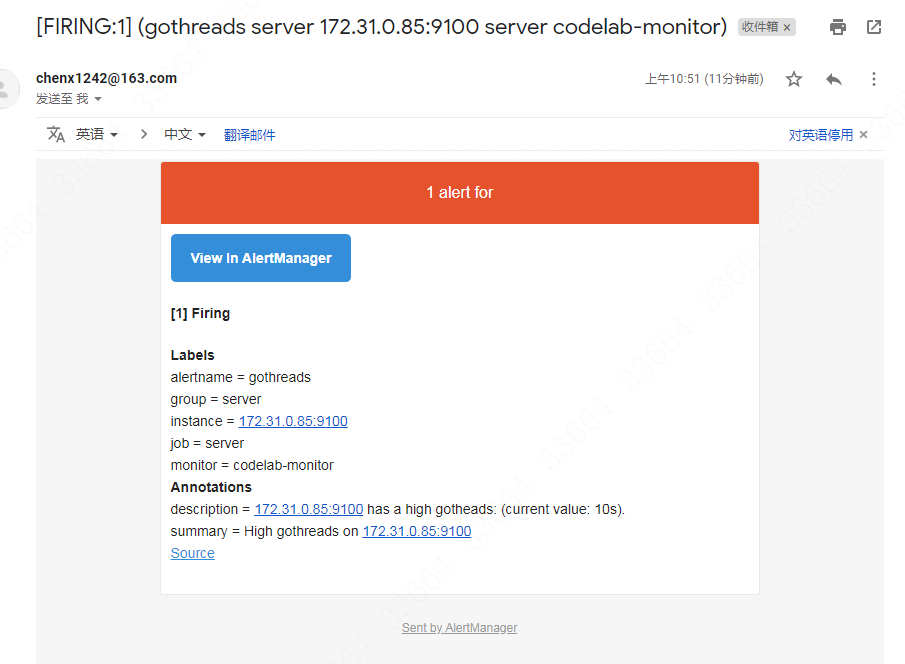
可见在告警邮件里是有在rules.yml配置的summary和description信息。
如果要用docker部署alertmanager的话,语句如下:
1
2
3
4docker run --name alertmanager --rm -d \
-v /宿主机路径/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
--net=host \
prom/alertmanager
为了方便,我们会配置一个模板,这样告警邮件看起来会更加直观,那么就在/mnt/alertmanager-0.19.0.linux-amd64目录下新建一个template文件夹,然后创建一个email.tmpl如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{{ define "email.html" }}
<table border="1">
<tr>
<td>报警项</td>
<td>实例</td>
<td>报警阀值</td>
<td>开始时间</td>
</tr>
{{ range $i, $alert := .Alerts }}
<tr>
<td>{{ index $alert.Labels "alertname" }}</td>
<td>{{ index $alert.Labels "instance" }}</td>
<td>{{ index $alert.Annotations "value" }}</td>
<td>{{ $alert.StartsAt }}</td>
</tr>
{{ end }}
</table>
{{ end }}
然后把上面alertmanager.yml里那几个#templates、#html、#headers的注释放开,重新启动alertmanager,一会就可以看到告警了: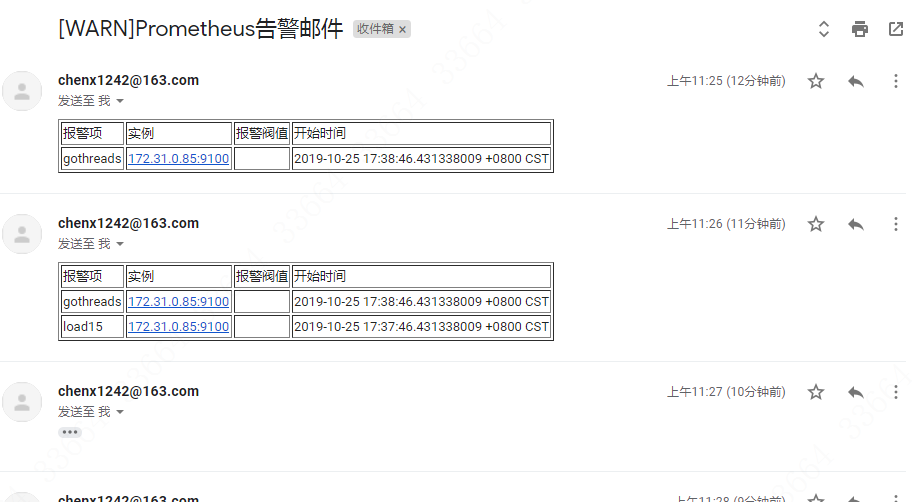
可见模板已经配置上了。
故障排错
Alertmanager前台启动后,会不停的刷如下的日志:
1
level=error ts=2019-10-25T06:50:16.470Z caller=dispatch.go:266 component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="Post http://127.0.0.1:5001/: dial tcp 127.0.0.1:5001: connect: connection refused"
这个的原因是alertmanager.yml默认情况下的配置是所有的告警都走一个叫web.hook的receiver,而这个receiver配置的就是本地5001端口,如下:
1
2
3
4receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
所以这个报警可以无视掉,等你配置了正确的告警方式就解决掉这个问题了。
参考资料
https://www.li-rui.top/2018/11/12/monitor/Prometheus%20Alertmanager%E4%BD%BF%E7%94%A8/
https://www.qikqiak.com/post/alertmanager-of-prometheus-in-practice/
https://www.aneasystone.com/archives/2018/11/prometheus-in-action.html

